This chapter provides a language reference for Nyquist. Operations
are categorized by functionality and abstraction level.
Nyquist is implemented in two important levels: the “high level” supports
behavioral abstraction, which means that operations like stretch and
at can be applied. These functions are the ones that typical users
are expected to use, and most of these functions are written in XLISP.
The “low-level” primitives directly operate on sounds, but know nothing of
environmental variables (such as *warp*, etc.). The
names of most of these low-level functions start with “snd-”. In
general, programmers should avoid any function with the “snd-”
prefix. Instead, use the “high-level” functions, which know about the
environment and react appropriately. The names of high-level functions
do not have prefixes like the low-level functions.
There are certain low-level operations that apply directly to sounds (as opposed to behaviors) and are relatively “safe” for ordinary use. These are marked as such.
Nyquist uses both linear frequency and equal-temperament pitch numbers to specify repetition rates. Frequency is always specified in either cycles per second (hz), or pitch numbers, also referred to as “steps,” as in steps of the chromatic scale. Steps are floating point numbers such that 60 = Middle C, 61 = C#, 61.23 is C# plus 23 cents, etc. The mapping from pitch number to frequency is the standard exponential conversion, and fractional pitch numbers are allowed:
frequency = 440 * 2((pitch - 69)/12)There are many predefined pitch names. By default these are tuned in equal temperament, with A4 = 440Hz, but these may be changed. (See Section Predefined Constants).
A sound is a primitive data type in Nyquist. Sounds can be created, passed as parameters, garbage collected, printed, and set to variables just like strings, atoms, numbers, and other data types.
Sounds have 5 components:
srate – the sample rate of the sound.samples – the samples.signal-start – the time of the first sample.signal-stop – the time of one past the last sample.logical-stop – the time at which the sound logically ends, e.g. a
sound may end at the beginning of a decay. This value defaults
to signal-stop,
but may be set to any value.
logical-start to indicate the
logical or perceptual beginning of a sound as well as a logical-stop
to indicate the logical ending of a sound. In practice, only
logical-stop is needed; this attribute tells when the next sound
should begin to form a sequence of sounds. In this respect, Nyquist sounds
are asymmetric: it is possible to compute sequences forward in time by
aligning the logical start of each sound with the logical-stop of the
previous one, but one cannot compute “backwards”, aligning the logical end
of each sound with the logical start of its successor. The root of this
asymmetry is the fact that when we invoke a behavior, we say when to start,
and the result of the behavior tells us its logical duration. There is no
way to invoke a behavior with a direct specification of when to
stop (Footnote 3) .
Note: there is no way to enforce the
intended “perceptual” interpretation of
logical-stop. As far as Nyquist is concerned, these are just numbers to
guide the alignment of sounds within various control constructs.Multichannel sounds are represented by Lisp arrays of sounds. To create an
array of sounds the XLISP vector function is useful. Most low-level
Nyquist functions (the ones starting with snd-) do not operate on
multichannel sounds. Most high-level functions do operate on multichannel
sounds.
Several functions display information concerning a sound and can be used to query the components of a sound. There are functions that access samples in a sound and functions that construct sounds from samples.
sref(sound, time) [SAL](sref sound time) [LISP]snd-samples below), or use
snd-srate and snd-t0 (see below) to find the sample rate
and starting time, and compute a time (t) from the sample number (n):
t = (n / srate) + t0Thus, the Lisp code to access the nth sample of a sound would look like:
(sref sound (global-to-local (+ (/ n (snd-srate sound)) (snd-t0 sound))))
Or in SAL, it would look like:
sref(sound, global-to-local(n / snd-srate(sound) + snd-t0(sound)))
Here is why sref interprets its time argument
as a local time (shown first in LISP and then in SAL syntax):
> (sref (ramp 1) 0.5) ; evaluate a ramp at time 0.5 0.5 SAL> print sref(ramp(1), 0.5) ; evaluate a ramp at time 0.5 0.5 > (at 2.0 (sref (ramp 1) 0.5)) ; ramp is shifted to start at 2.0 ; the time, 0.5, is shifted to 2.5 0.5 SAL> sref(ramp(1), 0.5) @ 2.0 ; ramp is shifted to start at 2.0 ; the time, 0.5, is shifted to 2.5 0.5
If you were to use snd-sref, which treats time as global, instead
of sref, which treats time as local, then the first example above
would return the same answer (0.5), but the second example would return
0. Why? Because the ramp behavior would be shifted to start at
time 2.0, but the resulting sound would be evaluated at global time
0.5. By definition, sounds have a value of zero before their start time.
sref-inverse(sound, value) [SAL](sref-inverse sound value) [LISP]snd-from-array(t0, sr,
array) [SAL](snd-from-array t0 sr array) [LISP]FLONUMs into a sound with starting
time t0 and sample rate sr. Safe for ordinary use. Be aware that
arrays of floating-point samples use 14 bytes per sample, and an additional
4 bytes per sample are allocated by this function to create a sound type.snd-fromarraystream(t0, sr, object) [SAL](snd-fromarraystream t0 sr object) [LISP]FLONUM), and the sample rate is
sr. The object is an XLISP object (see Section Objects for
information on objects.) A sound is returned. When the sound needs samples,
they are generated by sending the message :next to object. If
object returns NIL, the sound terminates. Otherwise, object
must return an array of FLONUMs. The values in these arrays are
concatenated to form the samples of the resulting sound.
There is no provision for object to specify the
logical stop time of the sound, so the logical stop time is the termination
time. snd-fromobject(t0, sr, object) [SAL](snd-fromobject t0 sr object) [LISP]FLONUM), and the sample rate is
sr. The object is an XLISP object (see Section Objects for
information on objects. A sound is returned. When the sound needs samples,
they are generated by sending the message :next to object. If
object returns NIL, the sound terminates. Otherwise, object
must return a FLONUM. There is no provision for object to specify the
logical stop time of the sound, so the logical stop time is the termination
time.snd-extent(sound, maxsamples) [SAL](snd-extent sound maxsamples) [LISP]snd-fetch(sound) [SAL](snd-fetch sound) [LISP]FLONUM after each call, or
NIL when sound terminates. Note: snd-fetch modifies
sound; it is strongly recommended to copy sound using
snd-copy and access only the copy with snd-fetch.snd-fetch-array(sound, len,
step) [SAL](snd-fetch-array sound len step)
[LISP]FLONUMs or NIL when the sound terminates. The len
parameter, a FIXNUM, indicates how many samples should be
returned in the result array. After the array is returned, sound
is modified by skipping over step (a FIXNUM) samples. If
step equals len, then every sample is returned once. If
step is less than len, each returned array will overlap the
previous one, so some samples will be returned more than once. If
step is greater than len, then some samples will be skipped
and not returned in any array. The step and len may change at
each call, but in the current implementation, an internal buffer is
allocated for sound on the first call, so subsequent calls may not
specify a greater len than the first. When an array is returned,
it will have len samples. If necessary, snd-fetch-array
will read zeros beyond the end of the sound to fill the array. When
this happens, *rslt* is set to a FIXNUM number of samples in
the array that were read from the sound before the physical stop time
of the sound. If all samples in the array are “valid” samples from
the sound (coming from the sound before the sound
terminates), *rslt* is set to NIL. The *rslt*
variable is global and used to return extra results from other
functions, so programs should not assume *rslt* is valid after
subsequent function calls. Note: snd-fetch-array modifies
sound; it is strongly recommended to copy sound using
snd-copy and access only the copy with snd-fetch-array.snd-flatten(sound, maxlen) [SAL](snd-flatten sound maxlen) [LISP]snd-length. You would use this function to force samples to be computed in memory. Normally, this is not a good thing to do, but here is one appropriate use: In the case of sounds intended for wavetables, the unevaluated
sound may be larger than the evaluated (and typically short) one.
Calling snd-flatten will compute the samples and allow the unit generators to be freed in the next garbage collection. Note: If a sound is computed from many instances of table-lookup oscillators, calling snd-flatten will free the oscillators and their tables. Calling (stats) will print how many total bytes have been allocated to tables.snd-length(sound, maxlen) [SAL](snd-length sound maxlen) [LISP]snd-maxsamp(sound) [SAL](snd-maxsamp sound) [LISP]peak, a replacement (Signal Operations).snd-play(expression) [SAL](snd-play expression) [LISP]s-save.
Meanwhile, since this function does not write samples to a file, it is
useful in determining how much time is spent calculating samples. See
s-save (Section Sound File Input and Output) for saving samples to a file, and
play (Section Sound File Input and Output) to play a sound. This function is
safe for ordinary use. Note that it does not accept multichannel sounds.
To time mult-channel sound computation, you might try applying
to-mono (see Section Miscellaneous Functions) to get a SOUND.snd-print-tree(sound) [SAL](snd-print-tree sound) [LISP]snd-samples(sound, limit) [SAL](snd-samples sound limit) [LISP]snd-from-array, it requires a total of slightly over 18 bytes per
sample.snd-srate(sound) [SAL](snd-srate sound) [LISP]snd-time(sound) [SAL](snd-time sound) [LISP]snd-t0
instead.snd-t0(sound) [SAL](snd-t0 sound) [LISP]snd-print(expression, maxlen) [SAL](snd-print expression maxlen) [LISP]snd-save, but samples appear in text on the screen instead of in
binary in a file. This function is intended for debugging.
Safe for ordinary use.snd-set-logical-stop(sound,
time) [SAL](snd-set-logical-stop sound time) [LISP]set-logical-stop or set-logical-stop-abs instead.snd-sref(sound, time) [SAL](snd-sref sound time) [LISP]sref instead.snd-stop-time(sound) [SAL](snd-stop-time sound) [LISP]soundp(sound) [SAL](soundp sound) [LISP]stats() [SAL](stats) [LISP]mem function. Safe for ordinary use. This is the only way to find out how much memory is being used by table-lookup oscillator instances.snd-set-max-audio-mem(bytes) [SAL](snd-set-max-audio-mem bytes) [LISP]These are all safe and recommended for ordinary use.
to-mono(sound) [SAL](to-mono sound) [LISP]sim (Section Combination and Time Structure) for more details on how
channels are summed.db-to-linear(x) [SAL](db-to-linear x) [LISP]db-to-vel(x [, float]) [SAL](db-to-vel x [float]) [LISP]nil and the result is a FIXNUM clipped to fall in the
legal range of 1-127, but if a non-nil value
is provided, the result is a FLONUM that is not
rounded or clipped. The input parameter must be a FIXNUM or
FLONUM. Sounds are not allowed.follow(sound, floor, risetime, falltime, lookahead) [SAL](follow sound floor risetime falltime lookahead) [LISP]snd-avg for a function that
can help to generate a low-sample-rate input for follow.
See snd-chase in Section Filters for a related filter.gate(sound,
lookahead, risetime, falltime, floor,
threshold) [SAL](gate sound lookahead risetime falltime floor threshold) [LISP]FLONUM in seconds). (The signal begins to drop when the signal
crosses threshold, not after lookahead.) Decay continues until
the value reaches floor (a FLONUM), at which point the decay
stops and the output value is held constant. Either during the decay or
after the floor is reached, if the signal goes above threshold, then
the ouptut value will rise to unity (1.0) at the point the signal crosses
the threshold. Because of internal lookahead, the signal actually begins
to rise before the signal crosses threshold. The rise is a
constant-rate exponential and set so that a rise from floor to unity
occurs in risetime. Similary, the fall is a constant-rate exponential
such that a fall from unity to floor takes falltime.noise-gate(sound [, lookahead, risetime, falltime, floor, threshold] [, rms: use-rms, link: link-option]) [SAL](noise-gate sound [lookahead risetime falltime floor threshold] [:rms use-rms :link link-option]) [LISP]gate. All parameters
except snd are optional and default values are lookahead:
0.5, risetime: 0.02, falltime: 0.5, floor: 0.01,
threshold: 0.01. The keyword parameters :rms and :link are
also optional with default values of use-rms: NIL (false) and
link-option: T (true). The result is the input snd, where
below-threshold segments of sound are silenced. If use-rms is non-NIL,
the threshold applies to the RMS of the sound computed with
10 ms non-overlapping rectangular windows. Otherwise, threshold applies
to the absolute value of each sample in sound. If link-option is
non-NIL, and if the input sound is multichannel, then a single gate
is computed and applied to all channels. The gate threshold is considered
to be exceeded when any channel would exceed the threshold and open
the gate. (In other words, whether use-rms or not, a maximum value is
computed from all the channels and used to control the gate.)hz-to-step(freq) [SAL](hz-to-step freq) [LISP]SOUND. The result has the same type as the argument. See also step-to-hz (below).linear-to-db(x) [SAL](linear-to-db x) [LISP]linear-to-vel(x [, float]) [SAL](linear-to-vel x [float]) [LISP]nil and the result is a FIXNUM clipped to fall in the
legal range of 1-127, but if a non-nil value
is provided, the result is a FLONUM that is not
rounded or clipped. The input parameter must be a FIXNUM or
FLONUM. Sounds are not allowed.log(x) [SAL](log x) [LISP]FLONUM). (See s-log for a version that operates on signals.)set-control-srate(rate) [SAL](set-control-srate rate) [LISP]*default-control-srate* and reinitializing the environment. Do not call this within any synthesis function (see the control-srate-abs transformation, Section Transformations).set-sound-srate(rate) [SAL](set-sound-srate rate) [LISP]*default-sound-srate* and reinitializing the environment. Do not call this within any synthesis function (see the sound-srate-abs transformation, Section Transformations).set-pitch-names() [SAL](set-pitch-names) [LIS]c0, cs0, df0, d0, ... b0,
c1, ... b7). A440 (the default tuning) is represented by
the step 69.0, so the variable a4 (fourth octave A) is set to 69.0.
You can change the tuning by
setting *A4-Hertz* to a
value (in Hertz) and calling set-pitch-names to reinitialize the pitch
variables. Note that this will result in non-integer step values. It does not
alter the mapping from step values to frequency. There is no built-in
provision for stretched scales or non-equal temperament, although users
can write or compute any desired fractional step values.step-to-hz(pitch) [SAL](step-to-hz pitch) [LISP]SOUND type representing a time-varying step number. The result is a FLONUM if pitch is a number, and a SOUND if pitch is a SOUND. See also hz-to-step (above).get-duration(dur) [SAL](get-duration dur) [LISP]*rslt* is set to the global time corresponding to local time zero.get-loud() [SAL](get-loud) [LISP]*loud* environment variable. If *loud* is a signal, it is evaluated at local time 0 and a number (FLONUM) is returned.get-sustain() [SAL](get-sustain) [LISP]*sustain* environment variable. If *sustain* is a signal, it is evaluated at local time 0 and a number (FLONUM) is returned.get-transpose() [SAL](get-transpose) [LISP]*transpose* environment variable. If *transpose* is a signal, it is evaluated at local time 0 and a number (FLONUM) is returned.get-warp() [SAL](get-warp) [LISP]*warp* environment variable. For
efficiency, *warp* is stored in three parts representing a shift,
a scale factor, and a continuous warp function. Get-warp is used
to retrieve a signal that maps logical time to real time. This signal
combines the information of all three components of *warp* into
a single signal. If the continuous warp function component is not present
(indicating that the time warp is a simple combination of at
and stretch transformations), an error is raised. This
function is mainly for internal system use. In the future,
get-warp will probably be reimplemented to always return
a signal and never raise an error.local-to-global(local-time) [SAL](local-to-global local-time) [LISP]round(x) [SAL](round x) [LISP]snd-set-latency(latency) [SAL](snd-set-latency latency) [LISP]FLONUM. The previous value is returned. The default is 0.3 seconds. To avoid glitches, the latency should be
greater than the time required for garbage collection and message printing and any other system activity external to Nyquist.vel-to-db(x) [SAL](vel-to-db x) [LISP]FIXNUM or
FLONUM but not a sound. The result is a FLONUM.vel-to-linear(x) [SAL](vel-to-linear x) [LISP]FIXNUM or
FLONUM but not a sound. The result is a FLONUM.
These behaviors take a sound and transform that sound according to the environment. These are useful when writing code to make a high-level function from a low-level function, or when cuing sounds which were previously created:
cue(sound) [SAL](cue sound) [LISP]*loud*, the starting time from *warp*, *start*,
and *stop* to sound.
cue-file(filename) [SAL](cue-file filename) [LISP]cue, except
the sound comes from the named file, samples from which are coerced to the current default *sound-srate* sample rate.sound(sound) [SAL](sound sound) [LISP]*loud*, *warp*,
*start*, and *stop* to sound.control(sound) [SAL](control sound) [LISP]sound, but by convention is used when sound is a control signal
rather than an audio signal.
These functions provide musically interesting creation behaviors that react to their environment; these are the “unit generators” of Nyquist:
const(value [, duration]) [SAL](const value [duration]) [LISP]*control-srate*. Every sample has the given value, and the default duration is 1.0. See also s-rest, which is equivalent to calling const with zero, and note that you can pass scalar constants (numbers) to sim, sum, and mult where they are handled more efficiently than constant functions.env(t1, t2, t4, l1, l2, l3,
[dur]) [SAL](env t1 t2 t4 l1 l2 l3 dur) [LISP]0.0. If dur is not supplied, then
1.0 is assumed. The envelope duration is the product of dur,
*stretch*, and *sustain*. If
t1 + t2 + 2ms + t4 is greater than the envelope
duration, then a two-phase envelope is
substituted that has an attack/release time ratio of t1/t4.
The sample rate of the returned sound is *control-srate*. (See
pwl for a more general piece-wise linear function generator.)
The effect of time warping is to warp the starting time and ending time.
The intermediate breakpoints are then computed as described above.exp-dec(hold, halfdec, length) [SAL](exp-dec hold halfdec length) [LISP]pwev (see Section Piece-wise Approximations). The envelope starts at 1 and is constant for hold seconds. It then decays with a half life of halfdec seconds until length. (The total duration is length.) In other words, the amplitude falls by half each halfdec seconds. When stretched, this envelope scales linearly, which means the hold time increases and the half decay time increases.force-srate(srate, sound) [SAL](force-srate srate sound) [LISP]resample.lfo(freq [, duration, table, phase]) [SAL](lfo freq duration table phase) [LISP]osc (below)
except this computes at the *control-srate* and frequency
is specified in Hz. Initial phase is specified in degrees, defaulting to zero.
The *transpose* and *sustain* is not
applied. The effect of time warping is to warp the starting and ending
times. The signal itself will have a constant unwarped frequency.fmlfo(freq [, table, phase]) [SAL](fmlfo freq [table phase]) [LISP]*control-srate* using a sound to specify a time-varying
frequency in Hz. Initial phase is a FLONUM in degrees. The duration of the result is determined by freq.maketable(sound) [SAL](maketable sound) [LISP]osc function (see
below). Currently, tables are limited to 100,000,000 samples. This limit is the compile-time constant max_table_len set in sound.h. A wavetable is a list of the form
(sound pitch-number periodic)where the first element is a sound, the second is the pitch of the sound (this is not redundant, because the sound may represent any number of periods), and the third element is
T if the sound is one period of
a periodic signal, or nil if the sound is a sample that should not
be looped. Wavetables are used by osc, osc, hzosc,
amosc, fmosc, lfo, and fmlfo.build-harmonic(n, table-size) [SAL](build-harmonic n table-size) [LISP]maketable to construct a wavetable suitable for osc and other oscillators.control-warp(warp-fn, signal, [wrate]) [SAL](control-warp warp-fn signal wrate) [LISP]*control-srate*. See sound-warp for an explanation of
wrate and high-quality warping.mult(beh1, beh2, ...) [SAL](mult beh1 beh2 ...) [LISP]scale function is used to scale the sound by the number. When sounds are multiplied, the resulting sample rate is the maximum sample rate of the factors.prod(beh1, beh2, ...) [SAL](prod beh1 beh2 ...) [LISP]mult.pan(sound, where) [SAL](pan sound where) [LISP](ramp) or simply a number (e.g. 0.5). In either case, where should range from 0 to 1, where 0 means pan completely left, and 1 means pan completely right. For intermediate values, the sound to each channel is scaled linearly. Presently, pan does not check its arguments carefully.prod(beh1, beh2, ...) [SAL](prod beh1 beh2 ...) [LISP]mult.resample(sound, srate) [SAL](resample sound srate) [LISP]force-srate, except
high-quality interpolation is used to prefilter and reconstruct the signal
at the new sample rate. Also, the result is scaled by 0.95 to reduce problems with
clipping. (See also sound-warp.)scale(scale, sound) [SAL](scale scale sound) [LISP]snd-scale, except that it handles multichannel sounds. Sample rates, start times, etc. are taken from sound.scale-db(db, sound) [SAL](scale-db db sound) [LISP]scale-srate(sound, scale) [SAL](scale-srate sound scale) [LISP]snd-xform (see Section Signal Operations).shift-time(sound, shift) [SAL](shift-time sound shift) [LISP]snd-xform (see Section Signal Operations).

Figure 5: The shift-time function shifts a sound in time
according to its shift argument.
sound-warp(warp-fn, signal [, wrate]) [SAL](sound-warp warp-fn signal [wrate]) [LISP]*sound-srate*.
See also control-warp.
If wrate is not NIL, it must be a number. The parameter indicates that
high-quality resampling should be used and specifies the sample rate for the
inverse of warp-fn. Use the lowest number you can.
(See below for details.) Note that high-quality resampling is
much slower than linear interpolation.
To perform high-quality resampling by a fixed ratio, as opposed to a
variable ratio allowed in sound-warp, use scale-srate to
stretch or shrink the sound, and then resample to restore the
original sample rate.
Sound-warp and control-warp both take the inverse of
warp-fn to get a function from real time to score time. Each sample
of this inverse is thus a score time; signal is evaluated at each of
these score times to yield a value, which is the desired result. The
sample rate of the inverse warp function is somewhat arbitrary. With linear
interpolation, the inverse warp function sample rate is taken to be the
output sample rate. Note, however, that the samples of the inverse warp
function are stored as 32-bit floats, so they have limited precision. Since
these floats represent sample times, rounding can be a problem. Rounding
in this case is equivalent to adding jitter to the sample times. Nyquist
ignores this problem for ordinary warping, but for high-quality warping, the
jitter cannot be ignored.
The solution is to use a rather low sample rate
for the inverse warp function. Sound-warp can then linearly
interpolate this signal using double-precision floats to minimize jitter
between samples. The sample rate is a compromise: a low sample rate
minimizes jitter, while a high sample rate does a better job of capturing
detail (e.g. rapid fluctuations) in the warp function. A good rule of thumb
is to use at most 1,000 to 10,000 samples for the inverse warp function. For
example, if the result will be 1 minute of sound, use a sample rate of
3000 samples / 60 seconds = 50 samples/second. Because Nyquist has no
advance information about the warp function, the inverse warp function
sample rate must be provided as a parameter. When in doubt, just try
something and let your ears be the judge.integrate(signal) [SAL](integrate signal) [LISP]slope(signal) [SAL](slope signal) [LISP]osc(pitch [, duration, table, phase]) [SAL](osc pitch [duration table phase]) [LISP]1.0
(second), table *table*,
phase 0.0. The default value of *table* is a sinusoid. Duration is stretched by *warp* and
*sustain*, amplitude is nominally 1, but scaled by *loudness*, the start time is logical time 0, transformed by *warp*, and the sample rate is *sound-srate*.
The effect of time-warping is to warp the starting and ending times only; the
signal has a constant unwarped frequency.table is 3-element list. See maketable for a detailed
description.snd-down and snd-up for resampling one-shot sounds to a desired sample rate. A future version of osc
will handle both cases.osc is called, memory is allocated for the table, and samples are copied from the sound (the first element of the list which is the table parameter) to the memory. Every instance of osc has a private copy of the table, so the total storage can become large in some cases, for example in granular synthesis with many instances of osc. In some cases, it may make sense to use snd-flatten (see Section Accessing and Creating Sound) to cause the sound to be fully realized, after which the osc and its table memory can be reclaimed by garbage collection. The partial function (see below) does not need a private table and does not use much space.partial(pitch, env) [SAL](partial pitch env) [LISP]*sound-srate*. The partial
function is faster than osc.sine(pitch [, duration]) [SAL](sine pitch [duration]) [LISP]*sound-srate*.
This function is like osc with
respect to transformations. The sine function is faster than
osc.hzosc(hz [, table, phase]) [SAL](hzosc hz [table phase]) [LISP]*table* and the default phase is 0.0
degrees. The default duration is 1.0, but this is stretched as
in osc (see above). The hz parameter may be a SOUND, in
which case the duration of the result is the duration of hz. The
sample rate is *sound-srate*.osc-saw(hz) [SAL](osc-saw hz) [LISP]*sound-srate*. The hz parameter may be a sound as in hzosc (see above).osc-tri(hz) [SAL](osc-tri hz) [LISP]*sound-srate*. The hz parameter may be a sound as in hzosc (see above).osc-pulse(hz, bias [, compare-shape]) [SAL](osc-pulse hz bias [compare-shape]) [LISP]-1 and +1, giving a pulse width from 0% (always at -1) to 100% (always at +1). When bias is zero, a square wave is generated. Bias may be a SOUND to create varying pulse width. If bias changes rapidly, strange effects may occur. The optional compare-shape defaults to a hard step at zero, but other shapes may be used to achieve non-square pulses. The osc-pulse behavior is written in terms of other behaviors and defined in the file nyquist.lsp using just a few lines of code. Read the code for the complete story.amosc(pitch, modulation [, table,
phase]) [SAL](amosc pitch modulation [table phase]) [LISP]*table*, and phase is the starting phase (default 0.0 degrees)
within osc-table. The sample rate is *sound-srate*. fmosc(pitch, modulation [, table,
phase]) [SAL](fmosc pitch modulation [table phase]) [LISP]*table*, and phase is the starting phase (default 0.0 degrees)
within osc-table. The modulation
is expressed in hz, e.g. a sinusoid modulation signal with an
amplitude of 1.0 (2.0 peak to peak), will cause a +/- 1.0 hz
frequency deviation in sound. Negative frequencies are correctly
handled. The sample rate is *sound-srate*. fmfb(pitch, index [, dur]) [SAL](fmfb pitch index [dur]) [LISP]SOUND or a FLONUM. If index is
a FLONUM, dur must be provided (a FLONUM) to specify
the duration. Otherwise, dur is ignored if present and the duration is
determined by that of index. The sample rate is *sound-srate*.
A sinusoid table is used.
If index is below 1.1, this generates a sawtooth-like waveform.buzz(n, pitch, modulation) [SAL](buzz n pitch modulation) [LISP]*sound-srate*.pluck(pitch [, duration, final-amplitude]) [SAL](pluck pitch [duration final-amplitude]) [LISP]*sound-srate*.siosc(pitch,
modulation, tables) [SAL](siosc pitch modulation tables) [LISP]fmosc. The tables specify a list of
waveforms as follows: (table0 time1 table2 ... timeN
tableN), where each table is a sound representing one period. Each
time is a time interval measured from the starting time. The time is
scaled by the nominal duration (computed using (local-to-global
(get-sustain))) to get the actual time. Note that this implies linear
stretching rather than continuous timewarping of the interpolation or the
breakpoints. The waveform is table0 at the starting time, table1
after time1 (scaled as described), and so on. The duration and logical
stop time is given by modulation. If modulation is shorter than
timeN, then the full sequence of waveforms is not used. If
modulation is longer than timeN, tableN is used after timeN
without further interpolation.sampler(pitch, modulation
[, sample, npoints]) [SAL](sampler pitch modulation [sample npoints]) [LISP]fmosc
described above. The optional sample (which defaults to 2048-point
sinusoid) is a list of the form
(sound pitch-number loop-start)where the first element is a sound containing the sample, the second is the pitch of the sample, and the third element is the time of the loop point. If the loop point is not in the bounds of the sound, it is set to zero. The optional npoints specifies how many points should be used for sample interpolation. Currently this parameter defaults to 2 and only 2-point (linear) interpolation is implemented. It is an error to modulate such that the frequency is negative. Note also that the loop point may be fractional. The sample rate is
*sound-srate*.
There are a number of related behaviors for piece-wise approximations
to functions. The simplest of these, pwl was mentioned earlier
in the manual. It takes a list of breakpoints, assuming an initial
point at (0, 0), and a final value of 0. An analogous piece-wise
exponential function, pwe, is provided. Its implicit starting
and stopping values are 1 rather than 0. Each of these has variants.
You can specify the initial and final values (instead of taking the
default). You can specify time in intervals rather than cummulative
time. Finally, you can pass a list rather than an argument list. This leads to 16 versions:
Piece-wise Linear Functions: Cummulative Time: Default initial point at (0, 0), final value at 0: pwl pwl-list Explicit initial value: pwlv pwlv-list Relative Time: Default initial point at (0, 0), final value at 0: pwlr pwlr-list Explicit initial value: pwlvr pwlvr-list Piece-wise Exponential Functions: Cummulative Time: Default initial point at (0, 1), final value at 1: pwe pwe-list Explicit initial value: pwev pwev-list Relative Time: Default initial point at (0, 1), final value at 1: pwer pwer-list Explicit initial value: pwevr pwevr-listAll of these functions are implemented in terms of
pwl (see nyquist.lsp for the implementations. There are infinite opportunities for errors in these functions: if you leave off a data point, try to specify points in reverse order, try to create an exponential that goes to zero or negative values, or many other bad things, the behavior is not well-defined. Nyquist should not crash, but Nyquist does not necessarily attempt to report errors at this time.pwl(t1, l1, t2, l2, ... tn) [SAL](pwl t1 l1 t2 l2 ... tn) [LISP]*sustain* (if
*sustain* is a SOUND, it is evaluated once at the starting
time of the envelope). Each breakpoint time is then mapped according to
*warp*. The result is a linear interpolation (unwarped) between
the breakpoints. The sample rate is *control-srate*. Breakpoint
times are quantized to the nearest sample time. If you specify one or more
breakpoints withing one sample period, pwl attempts to give a good
approximation to the specified function. In particular, if two breakpoints
are simultaneous, pwl will move one of them to an adjacent sample,
producing a steepest possible step in the signal. The exact details of this
“breakpoint munging” is subject to change in future versions. Please report
any cases where breakpoint lists give unexpected behaviors. The author will
try to apply the “principle of least surprise” to the design. Note that
the times are relative to 0; they are not durations of each envelope
segment.pwl-list(breakpoints) [SAL](pwl-list breakpoints) [LISP]apply to apply the pwl function to
the breakpoints, but if the list is very long (hundreds or thousands of
points), you might get a stack overflow because XLISP has a fixed-size
argument stack. Instead, call pwl-list, passing one argument, the
list of breakpoints.pwlv(l1, t2, l2, t3, t3, ... tn, ln) [SAL](pwlv l1 t2 l2 t3 l3 ... tn ln) [LISP]pwl.pwlv-list(breakpoints) [SAL](pwlv-list breakpoints) [LISP]pwlv that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwlr(i1, l1, i2, l2, ... in) [SAL](pwlr i1 l1 i2 l2 ... in) [LISP]pwl.pwlr-list(breakpoints) [SAL](pwlr-list breakpoints) [LISP]pwlr that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwlvr(l1, i2, l2, i3, i3, ... in, ln) [SAL](pwlvr l1 i2 l2 i3 i3 ... in ln) [LISP]pwlv.pwlvr-list(breakpoints) [SAL](pwlvr-list breakpoints) [LISP]pwlvr that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwe(t1, l1, t2, l2, ... tn) [SAL](pwe t1 l1 t2 l2 ... tn) [LISP]pwl, then exponentiates each resulting sample. A faster implementation is certainly possible!) Breakpoint values (lj) must be greater than zero. Otherwise, this function is similar to pwl, including stretch by *sustain*, mapping according to *warp*, sample rate based on *control-srate*, and "breakpoint munging" (see pwl described above). Default initial and final values are of dubious value with exponentials. See pwev below for the function you are probably looking for.pwe-list(breakpoints) [SAL](pwe-list breakpoints) [LISP]pwe that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwev(l1, t2, l2, t3, t3, ... tn, ln) [SAL](pwev l1 t2 l2 t3 t3 ... tn ln) [LISP]pwe. pwev-list(breakpoints) [SAL](pwev-list breakpoints) [LISP]pwev that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwer(i1, l1, i2, l2, ... in) [SAL](pwer i1 l1 i2 l2 ... in) [LISP]pwe. Consider using pwerv instead of this one.pwer-list(breakpoints) [SAL](pwer-list breakpoints) [LISP]pwer that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.pwevr(l1, i2, l2, i3, i3, ... in, ln) [SAL](pwevr l1 i2 l2 i3 i3 ... in ln) [LISP]pwev. Note that this is similar to the csound GEN05 generator. Which is uglier, GEN05 or pwevr?pwevr-list(breakpoints) [SAL](pwevr-list breakpoints) [LISP]pwevr that takes a single list of breakpoints as its argument. See pwl-list above for the rationale.
alpass(sound, decay, hz [, minhz]) [SAL](alpass sound decay hz [minhz]) [LISP]SOUND, the delay may be time-varying. Linear interpolation is then used for fractional sample delay, but it should be noted that linear interpolation implies a low-pass transfer function. Thus, this filter may behave differently with a constant SOUND than it does with a FLONUM value for hz. In addition, if hz is of type SOUND, then minhz is required. The hz parameter will be clipped to be greater than minhz, placing an upper bound on the delay buffer length.comb(sound, decay, hz) [SAL](comb sound decay hz) [LISP]feedback-delay (see below). The hz parameter must be a number greater than zero. It is used to compute delay, which is then rounded to the nearest integer number of samples (so the frequency is not always exact. Higher sampling rates yield better delay resolution.) The decay may be a sound or a number. In either case, it must also be positive. (Implementation note: an exponentiation is needed to convert decay into the feedback parameter for feedback-delay, and exponentiation is typically more time-consuming than the filter operation itself. To get high performance, provide decay at a low sample rate.) The resulting sound will have the start time, sample rate, etc. of sound.congen(gate, risetime, falltime) [SAL](congen gate risetime falltime) [LISP]FLONUM) seconds. During the decay, the half-time is falltime seconds. The sample rate, start time, logical stop, and terminate time all come from gate. If you want a nice decay, be sure that the gate goes to zero and stays there for awhile before gate terminates, because congen (and all Nyquist sounds) go immediately to zero at termination time. For example, you can use pwl to build a pulse followed by some zero time:
(pwl 0 1 duty 1 duty 0 1)
Assuming duty is less than 1.0, this will be a pulse of duration duty followed by zero for a total duration of 1.0.
(congen (pwl 0 1 duty 1 duty 0 1) 0.01 0.05)
will have a duration of 1.0 because that is the termination time of the pwl input. The decaying release of the resulting envelope will be truncated to zero at time 1.0. (Since the decay is theoretically infinite, there is no way to avoid truncation, although you could multiply by another envelope that smoothly truncates to zero in the last millisecond or two to get both an exponential decay and a smooth final transition to zero.)
convolve(sound,
response) [SAL](convolve sound response) [LISP]demos/convolution.htm. feedback-delay(sound, delay, feedback) [SAL](feedback-delay sound delay feedback) [LISP]lp(sound, cutoff) [SAL](lp sound cutoff) [LISP]tone(sound, cutoff) [SAL](tone sound cutoff) [LISP]lp instead, or define it by adding (setfn tone lp) to your program.hp(sound, cutoff) [SAL](hp sound cutoff) [LISP]lp.atone(sound, cutoff) [SAL](atone sound cutoff) [LISP]hp instead, or define it by adding (setfn atone hp) to your program.reson(sound, center, bandwidth [, n]) [SAL](reson sound center bandwidth [n]) [LISP]reson is to simulate resonances in the human vocal tract.
See demos/voice_synthesis.htm
for sample code and documentation.areson(sound, center, bandwidth [, n]) [SAL](areson sound center bandwidth [n]) [LISP]areson filter is an exact
complement of reson such that if both are applied to the
same signal with the same parameters, the sum of the results yeilds
the original signal.shape(signal, table, origin) [SAL](shape signal table origin) [LISP]FLONUM and gives the time which should be considered the origin of table. (This is important because table cannot have values at negative times, but signal will often have negative values. The origin gives an offset so that you can produce suitable tables.) The output at time t is:
table(origin + clip(signal(t))where clip(x) = max(1, min(-1, x)). (E.g. if table is a signal defined over the interval [0, 2], then origin should be 1.0. The value of table at time 1.0 will be output when the input signal is zero.) The output has the same start time, sample rate, etc. as signal. The
shape function will also accept multichannel signals and tables.
Further discussion and examples can be found in
demos/distortion.htm.
The shape
function is also used to map frequency to amplitude to achieve a spectral envelope for
Shepard tones in demos/shepard.lsp.biquad(signal, b0, b1, b2, a0, a1, a2) [SAL](biquad signal b0 b1 b2 a0 a1 a2) [LISP]FLONUMs. See also lowpass2, highpass2, bandpass2, notch2, allpass2, eq-lowshelf, eq-highshelf, eq-band, lowpass4, lowpass6, highpass4, and highpass8 in this section for convenient variations based on the same filter. The equations for the filter are: zn = sn + a1 * zn-1 + a2 * zn-2, and yn = zn * b0 + zn-1 * b1 + zn-2 * b2.biquad-m(signal, b0, b1, b2, a0, a1, a2) [SAL](biquad-m signal b0 b1 b2 a0 a1 a2) [LISP]FLONUMs.lowpass2(signal, hz [, q]) [SAL](lowpass2 signal hz [q]) [LISP]snd-biquad. The cutoff frequency is given by hz (a FLONUM) and an optional Q factor is given by q (a FLONUM).highpass2(signal, hz [, q]) [SAL](highpass2 signal hz [q]) [LISP]snd-biquad. The cutoff frequency is given by hz (a FLONUM) and an optional Q factor is given by q (a FLONUM).bandpass2(signal, hz [, q]) [SAL](bandpass2 signal hz [q]) [LISP]snd-biquad. The center frequency is given by hz (a FLONUM) and an optional Q factor is given by q (a FLONUM).notch2(signal, hz [, q]) [SAL](notch2 signal hz [q]) [LISP]snd-biquad. The center frequency is given by hz (a FLONUM) and an optional Q factor is given by q (a FLONUM).allpass2(signal, hz [, q]) [SAL](allpass2 signal hz [q]) [LISP]snd-biquad. The frequency is given by hz (a FLONUM) and an optional Q factor is given by q (a FLONUM).eq-lowshelf(signal, hz, gain [, slope]) [SAL](eq-lowshelf signal hz gain [slope]) [LISP]snd-biquad. The hz parameter (a FLONUM)is the halfway point in the transition, and gain (a FLONUM) is the bass boost (or cut) in dB. The optional slope (a FLONUM) is 1.0 by default, and response becomes peaky at values greater than 1.0.eq-highshelf(signal, hz, gain [, slope]) [SAL](eq-highshelf signal hz gain [slope]) [LISP]snd-biquad. The hz parameter (a FLONUM)is the halfway point in the transition, and gain (a FLONUM) is the treble boost (or cut) in dB. The optional slope (a FLONUM) is 1.0 by default, and response becomes peaky at values greater than 1.0.eq-band(signal, hz, gain, width) [SAL](eq-band signal hz gain width) [LISP]snd-biquad, eq-band-ccc and eq-band-vvv. The hz parameter (a FLONUM) is the center frequency, gain (a FLONUM) is the boost (or cut) in dB, and width (a FLONUM) is the half-gain width in octaves. Alternatively, hz, gain, and width may be SOUNDs, but they must all have the same sample rate, e.g. they should all run at the control rate or at the sample rate.lowpass4(signal, hz) [SAL](lowpass4 signal hz) [LISP]FLONUM).lowpass6(signal, hz) [SAL](lowpass6 signal hz) [LISP]FLONUM).lowpass8(signal, hz) [SAL](lowpass8 signal hz) [LISP]FLONUM).highpass4(signal, hz) [SAL](highpass4 signal hz) [LISP]FLONUM).highpass6(signal, hz) [SAL](highpass6 signal hz) [LISP]FLONUM).highpass8(signal, hz) [SAL](highpass8 signal hz) [LISP]FLONUM).tapv(sound, offset,
vardelay, maxdelay) [SAL](tapv sound offset vardelay maxdelay) [LISP]snd-tapv. See it for details (page Signal Operations).
nrev(sound, decay, mix) [SAL](nrev sound decay mix) [LISP]jcrev(sound, decay, mix) [SAL](jcrev sound decay mix) [LISP]prcrev(sound, decay, mix) [SAL](prcrev sound decay mix) [LISP]nrev, jcrev, and prcrev) are implemented
in STK (running within Nyquist). nrev derives from Common Music's
NRev, which consists of 6 comb filters followed by 3 allpass filters, a
lowpass filter, and another allpass in series followed by two allpass
filters in parallel. jcrev is the John Chowning
reverberator which is based on the use of networks of simple allpass
and comb delay filters. This reverb implements three series allpass units,
followed by four parallel comb filters, and two decorrelation delay
lines in parallel at the output. prcrev is a Perry Cook's
reverberator which is based on the Chowning/Moorer/Schroeder
reverberators using networks of simple allpass and comb delay filters.
This one implements two series allpass units and two parallel comb filters.
The sound input may be single or multichannel. The decay time is
in seconds, and mix sets the mixture of input sound reverb sound,
where 0.0 means input only (dry) and 1.0 means reverb only (wet).stkchorus(sound, depth, freq, mix [, delay]) [SAL](stkchorus sound depth freq mix [delay]) [LISP]FLONUM parameters depth and freq set
the modulation
depth from 0 to 1
and modulation frequency (in Hz), and mix sets the mixture
of input sound and chorused sound, where 0.0 means input sound only (dry)
and 1.0 means chorused sound only (wet). The parameter delay is a
FIXNUM representing the median desired delay length in samples. pitshift(sound, shift, mix) [SAL](pitshift sound shift mix) [LISP]SOUND is pitch-shifted by shift,
a FLONUM ratio. A value of 1.0 means no shift. The parameter mix
sets the mixture of input and shifted sounds. A value of 0.0
means input only (dry)
and a value of 1.0 means shifted sound only (wet).
clarinet(step, breath-env) [SAL](clarinet step breath-env) [LISP]FLONUM
that controls the tube length, and the breath-env (a SOUND)
controls the air pressure
and also determines the length of the resulting sound. The breath-env signal
should range from zero to one.clarinet-freq(step, breath-env, freq-env) [SAL](clarinet-freq step breath-env freq-env) [LISP]clarinet
that includes a variable frequency control, freq-env, which specifies
frequency deviation in Hz. The duration of the resulting sound is the minimum
duration of breath-env and freq-env. These parameters may be of type
FLONUM or SOUND. FLONUMs are coerced into SOUNDs
with a nominal duration arbitrarily set to 30.clarinet-all(step, breath-env, freq-env, vibrato-freq, vibrato-gain, reed-stiffness, noise) [SAL](clarinet-all step breath-env freq-env vibrato-freq vibrato-gain reed-stiffness noise) [LISP]clarinet-freq
that includes controls vibrato-freq (a FLONUM for vibrato frequency in Hertz),
vibrato-gain (a FLONUM for the amount of amplitude vibrato),
reed-stiffness (a FLONUM or SOUND controlling reed stiffness in the clarinet
model), and noise (a FLONUM or SOUND controlling noise amplitude in the input
air pressure). The vibrato-gain is a number from zero to one, where zero
indicates no vibrato, and one indicates a plus/minus 50% change in breath
envelope values. Similarly, the noise parameter ranges from zero to one where
zero means no noise and one means white noise with a peak amplitude of
plus/minus 40% of the breath-env. The reed-stiffness parameter varies
from zero to one.
The duration of the resulting sound is the minimum duration of
breath-env, freq-env, reed-stiffness, and noise. As with
clarinet-freq, these parameters may be either FLONUMs or
SOUNDs, and FLONUMs are coerced to sounds with a nominal
duration of 30.sax(step, breath-env) [SAL](sax step breath-env) [LISP]FLONUM
that controls the tube length, and the breath-env controls the air pressure
and also determines the length of the resulting sound. The breath-env signal
should range from zero to one.sax-freq(step, breath-env, freq-env) [SAL](sax-freq step breath-env freq-env) [LISP]sax
that includes a variable frequency control, freq-env, which specifies
frequency deviation in Hz. The duration of the resulting sound is the minimum
duration of breath-env and freq-env. These parameters may be of type
FLONUM or SOUND. FLONUMs are coerced into SOUNDs
with a nominal duration arbitrarily set to 30.sax-all(step, breath-env, freq-env, vibrato-freq, vibrato-gain, reed-stiffness, noise, blow-pos, reed-table-offset) [SAL](sax-all step breath-env freq-env vibrato-freq vibrato-gain reed-stiffness noise blow-pos reed-table-offset) [LISP]sax-freq
that includes controls vibrato-freq (a FLONUM for vibrato frequency in Hertz),
vibrato-gain (a FLONUM for the amount of amplitude vibrato),
reed-stiffness (a SOUND controlling reed stiffness in the sax
model), noise (a SOUND controlling noise amplitude in the input
air pressure), blow-pos (a SOUND controlling the point of excitation
of the air column), and reed-table-offset (a SOUND controlling a
parameter of the reed model). The vibrato-gain is a number from zero to one, where zero
indicates no vibrato, and one indicates a plus/minus 50% change in breath
envelope values. Similarly, the noise parameter ranges from zero to one where
zero means no noise and one means white noise with a peak amplitude of
plus/minus 40% of the breath-env. The reed-stiffness, blow-pos, and
reed-table-offset parameters all vary from zero to one.
The duration of the resulting sound is the minimum duration of
breath-env, freq-env, reed-stiffness, noise, breath-env,
blow-pos, and reed-table-offset. As with
sax-freq, these parameters may be either FLONUMs or
SOUNDs, and FLONUMs are coerced to sounds with a nominal
duration of 30.flute(step, breath-env) [SAL](flute step breath-env) [LISP]FLONUM that controls the tube
length, and the breath-env
controls the air pressure and also determines the starting time and
length of the resulting sound. The breath-env signal should
range from zero to one.flute-freq(step, breath-env, freq-env) [SAL](flute-freq step breath-env freq-env) [LISP]flute
that includes a variable frequency control, freq-env, which
specifies frequency deviation in Hz. The duration of the
resulting sound is the minimum duration of breath-env and
freq-env. These parameters may be of type FLONUM or
SOUND. FLONUMs are coerced into SOUNDs with a
nominal duration arbitrarily set to 30.flute-all(step,
breath-env, freq-env, vibrato-freq,
vibrato-gain, jet-delay, noise) [SAL](flute-all step breath-env freq-env vibrato-freq vibrato-gain jet-delay noise) [LISP]clarinet-freq that includes controls vibrato-freq (a
FLONUM for vibrato frequency in Hz), vibrato-gain (a
FLONUM for the amount of amplitude vibrato), jet-delay
(a FLONUM or SOUND controlling jet delay in the
flute model), and
noise (a FLONUM or SOUND controlling noise amplitude
in the input air pressure). The vibrato-gain is a number from zero
to one where zero means no vibrato, and one indicates a plus/minus
50% change in breath envelope values. Similarly, the noise parameter
ranges from zero to one, where zero means no noise and one means white
noise with a peak amplitude of
plus/minus 40% of the breath-env. The jet-delay is a ratio
that controls a delay length from the flute model, and therefore it
changes the pitch of the resulting sound. A value of 0.5 will maintain
the pitch indicated by the step parameter. The duration of the
resulting sound is the minimum duration of breath-env, freq-env,
jet-delay, and noise. These parameters may be either
FLONUMs or SOUNDs, and FLONUMs are coerced
to sounds with a nominal duration of 30. bowed(step, bowpress-env) [SAL](bowed step bowpress-env) [LISP]FLONUM
that controls the string length,
and the bowpress-env controls the bow pressure and also
determines the duration of the resulting sound. The bowpress-env
signal should range from zero to one.bowed-freq(step, bowpress-env, freq-env) [SAL](bowed-freq step bowpress-env freq-env) [LISP]bowed
that includes a variable frequency control, freq-env, which
specifies frequency deviation in Hz. The duration of the resulting
sound is the minimum duration of bowpress-env and freq-env.
These parameters may be of type FLONUM or SOUND.
FLONUMs are coerced into SOUNDs
with a nominal duration arbitrarily set to 30s.mandolin(step, dur, &optional detune) [SAL](mandolin step dur detune) [LISP]FLONUM wich specifies the desired pitch, dur
means the duration of the resulting sound and detune is a
FLONUM that controls the relative detune of the two strings.
A value of 1.0 means unison. The default value is 4.0.
Note: body-size (see snd-mandolin does not seem to
work correctly, so a default value is always used
by mandolin.wg-uniform-bar(step, bowpress-env) [SAL](wg-uniform-bar step bowpress-env) [LISP]wg-tuned-bar(step, bowpress-env) [SAL](wg-tuned-bar step bowpress-env) [LISP]wg-glass-harm(step, bowpress-env) [SAL](wg-glass-harm step bowpress-env) [LISP]wg-tibetan-bowl(step, bowpress-env) [SAL](wg-tibetan-bowl step bowpress-env) [LISP]FLONUM
that controls the resultant pitch, and bowpress-env is a SOUND ranging
from zero to one that controls a parameter of the model. In addition,
bowpress-env determines the duration of the resulting sound.
(Note: The bowpress-env does not seems influence the timbral
quality of the resulting sound).modalbar(preset, step, dur) [SAL](modalbar preset step dur) [LISP]MARIMBA, VIBRAPHONE, AGOGO, WOOD1,
RESO, WOOD2, BEATS, TWO-FIXED, or
CLUMP. The symbol must be quoted, e.g. for SAL syntax use
quote(marimba), and for Lisp syntax use 'marimba.
The parameter step is a FLONUM that
sets the pitch (in steps), and dur is the duration in seconds.sitar(step, dur) [SAL](sitar step dur) [LISP]FLONUM that sets the pitch,
and dur is the duration.stk-breath-env(dur, note-on note-off) [SAL](stk-breath-env dur note-on note-off) [LISP]CLARINET, where dur is the duration, note-on is the
attack time, and note-off is the decay time, all FLONUMs in seconds.
phasevocoder(s,
map, [fftsize, hopsize, mode]) [SAL](phasevocoder s map [fftsize hopsize mode])
[LISP]pv-time-pitch(s,
stretchfn, pitchfn, dur, [fftsize, hopsize, mode]) [SAL](pv-time-pitch s stretchfn pitchfn dur [fftsize hopsize mode]) [LISP]phasevocoder above). The
stretchfn gives the factor by which the input should be stretched at each
point in time; thus, the total duration is the integral of this function. The pitchfn specifies the amount by which pitch should be shifted at each
point in time. For example, where pitchfn is 2, the sample rate will be
doubled, increasing pitch and frequencies by an octave. The phase vocoder is
used to compensate for time stretching caused by resampling,
so stretchfn and pitchfn operate independently.
clip(sound, peak) [SAL](clip sound peak) [LISP]clip will return sound limited by peak. If sound is a multichannel sound, clip returns a multichannel sound where each channel is clipped. The result has the type, sample rate, starting time, etc. of sound.
Note: Many systems clip output when converting to fixed-point audio, e.g. 16-bit samples. Instead Nyquist simply takes the low-order 16 bits, allowing
samples to “wrap around.” This sounds terrible, but that is the point:
It is hard to miss when your samples go out of range. One use of this function
is to clip rather than wrap output. Warning: A floating point sample
value of 1.0 maps to
215
in 16-bit audio, but the maximum 16-bit sample
value is
215-1!
If your goal is to clip to the 16-bit range, you should
set peak to the ratio 32767.0/32768.0. For 24-bit audio, use
(223-1)/223, etc.s-abs(sound) [SAL](s-abs sound) [LISP]SOUND, compute the absolute value
of each sample. If sound is a number, just compute the absolute
value. If sound is a multichannel sound, return a multichannel
sound with s-abs applied to each element. The result has the
type, sample rate, starting time, etc. of sound.s-avg(sound, blocksize, stepsize, operation) [SAL](s-avg sound blocksize stepsize operation) [LISP]OP-AVERAGE) one half blocksize
earlier. You can correct for this shift by inserting one half
blocksize of silence before sound,
e.g. if s has a sample rate of 44100 Hz, then
snd-avg(seq(s-rest(0.01), cue(s)), 882, 441, OP-AVERAGE) will
shift s by 0.01 s to compensate for the shift introduced by a
smoothing window of size 0.02 s (882/44100).
If sound is a multichannel sound, return a multichannel
sound with s-avg applied to each element.
This function is useful for computing low-sample-rate rms or peak
amplitude signals for input to snd-gate or snd-follow.
To select the operation, operation should be one of OP-AVERAGE
or OP-PEAK. (These are global lisp variables; the actual
operation parameter is an integer.) For RMS computation, see
rms in Section More Behaviors.s-sqrt(sound) [SAL](s-sqrt sound) [LISP]SOUND, compute the square root of each sample. If sound is a number, just compute the square root. If sound is a multichannel sound, return a multichannel sound with s-sqrt applied to each element. The result has the type, sample rate, starting time, etc. of sound. In taking square roots, if an input sample is less than zero, the corresponding output sample is zero. This is done because the square root of a negative number is undefined.s-exp(sound) [SAL](s-exp sound) [LISP]SOUND, compute ex for each sample x. If sound is a number x, just compute ex. If sound is a multichannel sound, return a multichannel sound with s-exp applied to each element. The result has the type, sample rate, starting time, etc. of sound.s-log(sound) [SAL](s-log sound) [LISP]SOUND, compute ln(x) for each sample x. If sound is a number x, just compute ln(x). If sound is a multichannel sound, return a multichannel sound with s-log applied to each element. The result has the type, sample rate, starting time, etc. of sound. Note that the ln of 0 is undefined (some implementations return negative infinity), so use this function with care.s-max(sound1, sound2) [SAL](s-max sound1 sound2) [LISP]s-min(sound1, sound2) [SAL](s-min sound1 sound2) [LISP]osc-note(pitch [, duration, env, loud,
table]) [SAL](osc-note pitch [duration env loud table]) [LISP]osc, but osc-note
multiplies the result by env. The env may be a sound,
or a list supplying (t1 t2
t4 l1 l2 l3). The result has a sample rate of *sound-srate*.quantize(sound, steps) [SAL](quantize sound steps) [LISP]ramp([duration]) [SAL](ramp [duration]) [LISP]*Control-srate*. See Figure 6 for
more detail. Ramp is unaffected by the sustain transformation. The
effect of time warping is to warp the starting and ending times only. The
ramp itself is unwarped (linear). The sample rate is *control-srate*.rms(sound [, rate, window-size]) [SAL](rms sound [rate window-size]) [LISP]FLONUM and window-size is a FIXNUM.recip(sound) [SAL](recip sound) [LISP]SOUND, compute 1/x for each sample x. If sound is a number x, just compute 1/x. If sound is a multichannel sound, return a multichannel sound with recip applied to each element. The result has the type, sample rate, starting time, etc. of sound. Note that the reciprocal of 0 is undefined (some implementations return infinity), so use this function with care on sounds. Division of sounds is accomplished by multiplying by the reciprocal. Again, be careful not to divide by zero.
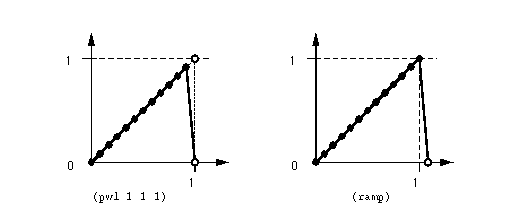
Figure 6: Ramps generated by pwl and ramp functions. The
pwl version ramps toward the breakpoint (1, 1), but in order to ramp
back to zero at breakpoint (1, 0), the function never reaches an amplitude
of 1. If used at the beginning of a seq construct, the next sound
will begin at time 1. The ramp version actually reaches breakpoint
(1, 1); notice that it is one sample longer than the pwl version. If
used in a sequence, the next sound after ramp would start at time 1 +
P, where P is the sample period.
s-rest([duration]) [SAL](s-rest [duration]) [LISP]*sound-srate*.
Default duration is 1.0 sec, and the sound is transformed in time according
to *warp*. Note: rest is a Lisp function that is equivalent to cdr. Be careful to use s-rest when you need a sound!noise([duration]) [SAL](noise duration) [LISP]*warp*. The
sample rate is *sound-srate* and the amplitude is +/- *loud*.yin(sound, minstep, maxstep, stepsize) [SAL](yin sound minstep maxstep stepsize) [LISP]SOUND.
The minstep, a FLONUM, is the minimum frequency considered (in steps),
maxstep, a FLONUM, is the maximum frequency considered (in steps), and
stepsize, a FIXNUM, is the desired hop size. The result is
a “stereo” signal,
i.e. an array of two SOUNDs, both at the same sample rate, which is
approximately the sample rate of sound divided by stepsize.
The first SOUND consists of frequency estimates (in units of
steps, i.e. middle C = 60). The second sound consists
of values that measure the confidence or reliability of the frequency estimate.
A small value (less than 0.1) indicates fairly high confidence. A larger value
indicates lower confidence. This number can also be thought of as a ratio of
non-periodic power to periodic power. When the number is low, it means the signal
is highly periodic at that point in time, so the period estimate will be
reliable.
Hint #1: See
Alain de Cheveigne and Hideki Kawahara's article "YIN, a Fundamental Frequency
Estimator for Speech and Music" in the Journal of the
Acoustic Society of America, April 2002 for details on the yin algorithm.
Hint #2: Typically, the stepsize should be at least the expected number
of samples in one period so that the
fundamental frequency estimates are calculated at a rate far below
the sample rate of the signal. Frequency does not change rapidly and
the yin algorithm is fairly slow. To optimize speed,
you may want to use less than 44.1 kHz sample rates for input sounds. Yin
uses interpolation to achieve potentially fractional-sample-accurate estimates,
so higher sample rates do not necessarily help the algorithm and definitely
slow it down. The computation time is O(n2) per estimate,
where n is the number
of samples in the longest period considered. Therefore, each increase
of minstep by 12 (an octave) gives you a factor of 4 speedup, and
each decrease of the sample rate of sound by a factor of
two gives you another factor of 4 speedup. Finally, the number of estimates is
inversely proportional to stepsize.
Hint #3: Use snd-srate (see Section Accessing and Creating Sound) to get
the exact sample rate of the result, which will be the sample rate of
sound divided by stepsize.
E.g. (snd-srate (aref yin-output 0)),
where yin-output is a result returned by yin, will be the
sample rate of the estimates.
These functions change the environment that is seen by other high-level
functions. Note that these changes are usually relative to the
current environment. There are also “absolute” versions of each
transformation function, with the exception of seq,
seqrep, sim, and simrep. The
“absolute” versions (starting or ending with “abs”) do not look at the
current environment, but rather set an environment variable to a specific value.
In this way, sections of code can be insulated from external
transformations.
abs-env(beh) [SAL](abs-env beh) [LISP](at 10.0 (abs-env (my-beh))) is equivalent to
(abs-env (my-beh)) because abs-env forces the default environment. Or in SAL, we would say abs-env(my-beh()) @ 10 is equivalent to abs-env(my-beh()).at(time, beh) [SAL](at time beh) [LISP]*warp* shifted by time. In SAL, you can use the infix
operator @ as in beh @ time. To discover how the
environment is shifting time, use local-to-global(time). Most
commonly, you call local-to-global(0) to find when a sound created
in the current environment will start, expressed in absolute (global) terms.
This can be regarded as the “current time.”at-abs(time, beh) [SAL](at-abs time beh) [LISP]*warp* shifted so that local time 0 maps to time. In SAL, you can use the infix operator @@ as in beh @@ time.continuous-control-warp(beh) [SAL](continuous-control-warp beh) [LISP]*control-srate*. Linear interpolation is currently used. Implementation: beh is first evaluated without any shifting, stretching, or warping. The result is functionally composed with the inverse of the environment's warp function.continuous-sound-warp(beh) [SAL](continuous-sound-warp beh) [LISP]*sound-srate*. Linear interpolation is currently used. See continuous-control-warp for implementation notes.control-srate-abs(srate,
beh) [SAL](control-srate-abs srate beh) [LISP]*control-srate*
set to sample rate srate. Note: there is no “relative” version of
this function.extract(start, stop, beh) [SAL](extract start stop beh) [LISP]*warp*. The result is shifted
to start according to *warp*, so normally the result will start without a delay of start.extract-abs(start, stop, beh) [SAL](extract-abs start stop beh) [LISP]*warp*. The result is shifted
to start according to *warp*.loud(volume, beh) [SAL](loud volume beh) [LISP]*loud*
incremented by volume. (Recall that *loud* is in decibels, so increment is the proper operation.)loud-abs(volume, beh) [SAL](loud-abs volume beh) [LISP]*loud*
set to volume.sound-srate-abs(srate, beh) [SAL](sound-srate-abs srate beh) [LISP]*sound-srate* set to sample rate srate. Note: there is no “relative” version of this function. stretch(factor, beh) [SAL](stretch factor beh) [LISP]*warp* scaled by factor. The effect is to “stretch” the result
of beh (under the current environment) by factor. See Chapter
Continuous Transformations and Time Warps for more information. Use get-duration(dur) to
get the nominal actual duration of a behavior that locally has a duration
of dur. Here, “nominal” means what would be expected if the behavior
obeys the shift, stretch, and warp components of the environment. (Any
behavior is free to deviate from the nominal timing. For example, a percussion
sound might have a fixed duration independent of the stretch factor.) Also,
“actual” means global or absolute time, and “locally” means within the
environment where get-duration is called. get-duration works
by mapping the current time (local time 0) using local-to-global to
obtain an actual start time, and mapping dur to obtain an actual end time.
The difference is returned.stretch-abs(factor, beh) [SAL](stretch-abs factor beh) [LISP]*warp* set to a linear time transformation where each unit of logical time maps to factor units of real time. The effect is to stretch the nominal behavior of beh (under the default global environment) by factor. See Chapter Continuous Transformations and Time Warps for more information.sustain(factor, beh) [SAL](sustain factor beh) [LISP]*sustain* scaled by factor. The effect is to “stretch” the result of beh (under the current environment) by factor; however, the logical stop times are not stretched. Therefore, the overall duration of a sequence is not changed, and sounds will tend to overlap if *sustain* is greater than one (legato) and be separated by silence if *sustain* is less than one.sustain-abs(factor, beh) [SAL](sustain-abs factor beh) [LISP]*sustain* set to factor. (See sustain, above.)transpose(amount, beh) [SAL](transpose amount beh) [LISP]*transpose* shifted by amount. The effect is relative transposition by amount semitones.transpose-abs(amount, beh) [SAL](transpose-abs amount beh) [LISP]*transpose* set to amount. The effect is the transposition of the nominal pitches in beh (under the default global environment) by amount.warp(fn, beh) [SAL](warp fn beh) [LISP]*warp* modified by fn. The idea is that beh and fn are written in the same time system, and fn warps that time system to local time. The current environment already contains a mapping from local time to global (real) time. The value of *warp* in effect when beh is evaluated is the functional composition of the initial *warp* with fn.warp-abs(fn, beh) [SAL](warp-abs fn beh) [LISP]*warp* set to fn. In other words, the current *warp* is ignored and not composed with fn to form the new *warp*.
These behaviors combine component behaviors into structures, including
sequences (melodies), simultaneous sounds (chords), and structures based
on iteration. See also the trigger function, described in
Section Starting and Stopping Sounds, which uses a SOUND to trigger instances of a behavior.
seq(beh1 [, beh2, ...]) [SAL](seq beh1 [beh2 ...]) [LISP]logical-stop time of the previous one. The results are summed to form a
sound whose logical-stop is
the logical-stop of the last behavior in the sequence. Each behavior
can result in a multichannel sound, in which case, the logical stop time is
considered to be the maximum logical stop time of any channel. The number
of channels in the result is the number of channels of the first behavior.
If other behaviors return fewer channels, new channels are created containing
constant zero signals until the required number of channels is obtained. If
other behaviors return a simple sound rather than multichannel sounds, the
sound is automatically assigned to the first channel of a multichannel sound
that is then filled out with zero signals. If another behavior returns more
channels than the first behavior, the error is reported and the computation
is stopped. Sample rates are converted up or down to match the sample rate of the first sound in a sequence.
Nyquist programs should generally avoid storing sounds in global variables
because that tends to cause sound samples to be retained in memory. A
related problem can occur with seq and seqrep. With these
functions, behaviors are not evaluated until needed, but what if the behaviors
depend on local variables as parameters? Ordinarily, the variables would
be long gone and garbage collected by the time the behavior is evaluated.
So, seq and seqrep capture all local variables and their
bindings (values) in closures. This solves the problem of retaining
local variables and values until they are needed by the behaviors, but it
has a problem similar to global variables in that any sounds captured in
the closure cannot be released until the last behavior in the sequence is
evaluated.
Here is an example:
load "reverb" function long-tone() return buzz(15, c4, lfo(5, 10)) function rev-with-tail(s, rt) return reverb(seq(s, s-rest(rt * 2)), rt) play rev-with-tail(pluck(c4), 10)
This SAL function uses seq to append
rt * 2 seconds of silence to sound s before passing it
to reverb ensuring that the reverb tail will not be cut off
immediately at the end of s. Behavior 2, s-rest(rt * 2), is
wrapped in a closure which also captures the binding of s to
the input sound (returned from long-tone()) and that of rt to 10.
If there were no closure, then
when rev-with-tail returns a sound to play, the variable
s would be freed by garbage collection, and the only remaining
reference to long-tone() would be internal to the reverb
sound computation. reverb disposes of samples as soon as they
are computed and used, so the total memory requirements would be minimal.
In this case, however, since s is captured in a closure,
as reverb demands computation of samples from
long-tone(), reverb releases its claim on the samples,
but s does not, so all the samples are retained in memory
until s-rest(rt * 2) is evaluated and the closure (and s)
are freed.
For 10 seconds of sound (such as long-tone()), this is not a big
problem. In fact, if you use the default settings for autonorm, Nyquist
will store about 20 seconds of sound in memory anyway just to do some
look-ahead for normalization, but if s represents an hour-long
stereo recording,
or if there are many other sounds bound in local variables and captured
in closures, the memory overhead can be too great. The solution is to
override the default scopes and bindings to achieve the variable
lifetimes we want. At any time, we can set a variable to nil,
freeing the previous value to allow garbage collection. In LISP, we
can write (prog1 s (setf s nil)) to evaluate s, then
free s by setting it to nil. The original value of s
is returned from the prog1 expression.
In SAL, we can use the same trick, using
setf rather than the typical SAL assignment operator
(=).
To change the example to be memory efficient, we change the definition
of rev-with-tail to:
function rev-with-tail(s, rt) return reverb(seq(prog1(s, setf(s, nil)), s-rest(rt * 2)), rt)
Note in this example that the variable s loses its reference to the
long-tone() sound right after it is evaluated by prog1,
so now reverb has the only reference to this sound, and it can
free samples from long-tone() as they are
consumed. (In case you are wondering, the actual mechanism is that when
reverb frees samples, their reference count goes to zero since no
other reference exists to the possibly shared list of samples. There is
no other reference because the reference previously bound to s
is released by the garbage collector.)
It should be noted that the variable rt is retained in the
closure and remains accessible there, so when s
terminates, s-rest(rt)
will evaluate as expected, using the value that rt acquired way
back when rev-with-tail was called. This illustrates why
the local variables must be saved in closures at the time seq is called.
seqrep(var, limit, beh) [SAL](seqrep (var limit) beh) [LISP]seq. The symbol var is
a read-only local variable to beh. Assignments are not restricted
or detected, but may cause a run-time error or crash. In LISP, the syntax is
(seqrep (var limit) beh).sim([beh1, beh2, ...]) [SAL](sim [beh1 beh2 ...]) [LISP]*warp*. If behaviors return multiple channel sounds,
the corresponding channels are added. If the number of channels does
not match, the result has as many channels as the argument with the
most channels. For example, if a two-channel
sound [L, R] is added to a four-channel sound [C1, C2, C3, C4], the
result is [L + C1, R + C2, C3, C4]. Arguments to sim may also
be numbers. If all arguments are numbers, sim is equivalent
(although slower than) the LISP + function. If a number is added to
a sound, snd-offset is used to add the number to each sample of
the sound. The result of adding a number to two or more sounds with
different durations is not defined. Use const to coerce a
number to a sound of a specified duration. An important limitation of
sim is that it cannot handle hundreds of behaviors due to a
stack size limitation in XLISP. To compute hundreds of sounds
(e.g. notes) at specified times, see timed-seq, below. See
also sum below. Notce that sim is not transitive due to
coercion rules: Using SAL syntax, sim(a, sim(b, c)) may not produce the
same result as sim(sim(a, b), c).simrep(var, limit, beh) [SAL](simrep var limit beh) [LISP]sim.
In LISP, the syntax is
(seqrep (var limit) beh).set-logical-stop(beh, time) [SAL](set-logical-stop beh time) [LISP]sum(a [, b, ...])[SAL](sum a [b ...]) [LISP]sim just above for more
detail.mult(a [, b, ...]) [SAL](mult a [b ...]) [LISP]diff(a, b) [SAL](diff a b) [LISP](sum a (prod -1 b)).timed-seq(score) [SAL](timed-seq score) [LISP]`((time1 stretch1 beh1) (time2
stretch2 beh2) ...), where timeN is the starting time,
stretchN is the stretch factor, and behN is the behavior. Note
that score is normally a quoted list! The times must be in
increasing order, and each behN is evaluated using lisp's eval,
so the behN behaviors cannot refer to local parameters or local
variables. The advantage of this form over seq is that the
behaviors are evaluated one-at-a-time which can take much less stack
space and overall memory. One special “behavior” expression is
interpreted directly by timed-seq: (SCORE-BEGIN-END)
is ignored, not evaluated as a function. Normally, this special
behavior is placed at time 0 and has two parameters: the score
start time and the score end time. These are used in Xmusic
functions. If the behavior has a :pitch keyword parameter
which is a list, the list represents a chord, and the expression is
replaced by a set of behaviors, one for each note in the chord.
It follows that if :pitch is nil, the behavior
represents a rest and is ignored.
play sound [SAL](play sound) [LISP]play is a command in SAL. In XLISP, it is a function,
so the syntax is (play sound), and in SAL, you can call the
XLISP function as #play(sound).
The play command or function
writes a file and plays it. The sound is any expression that
evaluates to a SOUND. Typically, this should be function call,
in which case the samples are computed incrementally and not retained in main memory (an advantage for large sounds). If the expression is a variable containing a SOUND (which may or may not be fully evaluated yet), the SOUND is fully evaluated and all samples are retained in the variable. The
play function is defined in the file
system.lsp. The variable *default-sf-dir*
names a directory into which to save a sound file. Be careful not to call play or sound-play within a function and then
invoke that function from another play command.
By default, Nyquist will try to normalize sounds using the method named by
*autonorm-type*, which is 'lookahead by default.
The lookahead method precomputes and buffers *autonorm-max-samples*
samples, finds the peak value, and normalizes accordingly. The
'previous method bases the normalization of the current sound on the peak value of the (entire) previous sound. This might be good if you are working with long sounds that start rather softly. See Section Memory Space and Normalization for more details.
If you want precise control over output levels, you should turn this feature off by typing (using SAL syntax):
autonorm-off()
Reenable the automatic normalization feature by typing:
autonorm-on()
Play normally produces real-time output. The default is to send audio data to the DAC as it is computed in addition to saving samples in a file. If computation is slower than real-time, output will be choppy, but since the samples end up in a file, you can type (r) to replay the stored sound. Real-time playback can be disabled by (using SAL syntax):
sound-off()
and reenabled by:
sound-on()
Disabling real-time playback has no effect on (play-file) or (r).
While sounds are playing, typing control-A to Nyquist (or clicking the Mark button in the NyquistIDE) will push the estimated
elapsed audio time onto the head of the list
stored in *audio-markers*.
Because samples are computed in blocks and because there is latency
between sample computation and sample playback, the elapsed time may not
be too accurate, and the computed elapsed time may not advance after all
samples have been computed but the sound is still playing.
play-file(filename) [SAL](play-file filename) [LISP]s-read function is used to read the file, and unless
filename specifies an absolute path or starts with “.”, it will be read from
*default-sf-dir*.autonorm-on() [SAL](autonorm-on) [LISP]play command.autonorm-off() [SAL](autonorm-off) [LISP]play command.sound-on() [SAL](sound-on) [LISP]play command.sound-off() [SAL](sound-off) [LISP]play command.s-save(expression, [maxlen, filename, progress], format: format, mode: mode, bits: bits, swap: flag, play: play) [SAL](s-save expression [maxlen filename progress] :format format :mode mode :bits bits :swap flag :play play) [LISP]*default-sound-file* is used instead.) A
FLONUM is returned giving the maximum absolute value of all samples
written. (This is useful for normalizing sounds and detecting sample
overflow.) If play is not NIL, the sound will be output
through the computer's audio output system. (play: [SAL]
or :play [LISP] is not implemented on all systems; if it is implemented, and filename is NIL, then this will play the file without also writing a file.)
The latency (length of audio buffering) used to play the sound is 0.3s by default, but see snd-set-latency.
If
a multichannel sound (array) is written, the channels are up-sampled to the
highest rate in any channel so that all channels have the same sample rate.
The maximum number of samples written per channel is optionally given by maxlen,
which allows writing the initial part of a very long or infinite sound.
Progress is indicated by printing the sample count after
writing each 10 seconds of frames. If progress is specified and greater
than 10,000, progress is printed at this specified frame count increment.
A header is written according to format, samples are encoded according to
mode, using bits bits/sample, and bytes are swapped if flag is not NIL. Defaults for these are
*default-sf-format*, *default-sf-mode*, and
*default-sf-bits*. The default for flag is NIL.
The bits parameter may be 8, 16, or 32. The values for the format and mode options are described below:
snd-head-nonesnd-head-rawsnd-head-AIFFsnd-head-IRCAMsnd-head-NeXTsnd-head-Wavesnd-head-WaveXsnd-head-flacsnd-head-oggsnd-head-*nyquist/runtime directory
for more formats. The current list includes
paf, svx, nist, voc, w64, mat4, mat5,
pvf, xi, htk, sds, avr, sd2, and caf.
snd-mode-adpcmsnd-mode-pcmsnd-mode-ulawsnd-mode-alawsnd-mode-floatsnd-mode-upcmsnd-mode-*nyquist/runtime for more modes. The current list includes
double, gsm610, dwvw, dpcm, and msadpcm.
The defaults for format, mode, and bits are as follows:
snd-head-NeXT, snd-mode-pcm,
16
snd-head-AIFF, snd-mode-pcm, 16
s-read(filename, time-offset: offset, srate: sr, dur: dur, nchans: chans, format: format, mode: mode, bits: n, swap: flag) [SAL](s-read filename :time-offset offset :srate sr
:dur dur :nchans chans :format format :mode mode :bits n
:swap flag) [LISP]*default-sf-dir* applies. If a header is
detected, the header is used to determine the format
of the file, and header information overrides format information provided by
keywords (except for time-offset: and dur:).
s-read("mysound.snd", srate: 44100)
specifies a sample rate of 44100 hz, but if the file has a header specifying 22050 hz, the resulting sample rate will be 22050. The parameters are:
*default-sf-srate* , which is normally 44100.s-save for details.
Default is *default-sf-format*, although this parameter is currently
ignored.s-save for details. Default is *default-sf-format*.s-save for
details. Default is *default-sf-bits*.NIL is returned rather than a sound. Information
about the sound is also returned by s-read
through *rslt* (Footnote 4) . The list assigned
to *rslt* is of the form: (format channels mode bits swap samplerate duration flags), which are defined as follows:
s-save for details. Access
this element of *rslt* by calling snd-read-format(*rslt*).*rslt* by calling snd-read-channels(*rslt*).*rslt* by calling snd-read-mode(*rslt*).
See s-save for details.*rslt* by calling snd-read-bits(*rslt*).*rslt* by calling snd-read-swap(*rslt*).FLONUM. Access
this element of *rslt* by calling snd-read-srate(*rslt*).*rslt* by calling snd-read-dur(*rslt*).s-read. If a value is actually
read from the sound file header, a flag is set. The flags
are: snd-head-type (format), snd-head-channels, snd-head-mode, snd-head-bits, snd-head-srate, and snd-head-dur. For example,
(let ((flags (s-read-flags *rslt*))) (not (zerop (logand flags snd-head-srate))))
tells whether the sample rate was specified in the file. See also sf-info below.
Access this element of *rslt* by calling snd-read-flags(*rslt*).
s-add-to(expression, maxlen, filename [, offset, progress]) [SAL](s-add-to expression maxlen filename [offset progress]) [LISP]*default-sf-dir* applies. A FLONUM is returned,
giving the maximum absolute value of all samples written. The
sample rate(s) of expression must match those of the file.
The maximum number of samples written per channel is given by maxlen,
which allows writing the initial part of a very long or infinite sound.
If offset is specified, the new sound is added to the file beginning at
an offset from the beginning (in seconds).
Progress is indicated by printing the sample count after
writing each 10 seconds of frames. If progress is specified and greater
than 10,000, progress is printed at this specified frame count increment.
The file is extended if
necessary to accommodate the new addition, but if offset
falls outside of the original file, the file is not modified. (If necessary,
use s-add-to to extend the file with zeros.)
The file must be a recognized
sound file with a header (not a raw sound file).s-overwrite(expression, maxlen, filename [, offset, progress]) [SAL](s-overwrite expression maxlen filename [offset progress]) [LISP]*default-sf-dir* applies.
A FLONUM is returned, giving the maximum absolute value of all
samples written. The
sample rate(s) of expression must match those of the file.
The maximum number of samples written per channel is given by maxlen,
which allows writing the initial part of a very long or infinite sound.
If offset is specified, the new sound is written to the file beginning at
an offset from the beginning (in seconds). The file is extended if
necessary to accommodate the new insert, but if offset falls outside of
the original file, the file is not modified. (If necessary, use
s-add-to to extend the file with zeros.)
Progress is indicated by printing the sample count after
writing each 10 seconds of frames. If progress is specified and greater
than 10,000, progress is printed at this specified frame count increment.
The file must be a recognized
sound file with a header (not a raw sound file).sf-info(filename) [SAL](sf-info filename) [LISP]soundfilename below) unless the filename begins with “.” or “/”. The source for this function is in the runtime and provides an example of how to determine sound file parameters. soundfilename(name) [SAL](soundfilename name) [LISP]*default-sf-dir* is prepended to name. The s-plot, s-read, and s-save functions all use soundfilename to translate filenames.s-plot(sound
[, dur, n]) [SAL](s-plot sound
[dur n]) [LISP]plot program on a Unix workstation, but now is
primarily used with NyquistIDE, which has self-contained plotting. Normally,
time/value pairs in ascii are written to points.dat and system-dependent code
(or the NyquistIDE program) takes it from there. If the sound is
longer than the optional dur (default is 2 seconds), only the
first dur seconds are plotted.
If there are more than n samples to be plotted, the signal is interpolated
to have n samples before plotting.
The data file used is *default-plot-file*:*default-plot-file*spec-plot(sound [, offset, res: res, bw: bw, db: db]) [SAL](spec-plot sound [offset :res res :bw bw :db db]) [LISP]*spec-plot-res*. Since one
is often interested in lower frequencies, the bw (bandwidth keyword parameter
limits the range of bins which are plotted, and defaults to *spec-plot-bw*.
The output can be presented on a dB scale by setting the db keyword parameter to
t (true). The defaults is to use a linear scale.
The optional offset (in seconds) skips initial samples before taking a frame of
samples from sound. The magnitude spectrum is sent to s-plot as a signal.
The sample rate of the signal is set so that the plot labels on the horizontal axis
represent Hz (not bin numbers.) To align bins with grid lines, one normally specifies
res values in round numbers, e.g. 10 or 20. To achieve an arbitrary bin size,
spec-plot resamples sound to a carefully computed sample rate that, after
a power-of-2-sized FFT, yields the desired bin size.*spec-plot-res*spec-plot. Defaults to 20 Hz. You
can override this by using a keyword parameter when you call spec-plot, or for
convenience, you can change this variable which will affect all future calls to
spec-plot where the keyword parameter is omitted.*spec-plot-bw*spec-plot. Defaults to 8000 Hz. You
can override this by using a keyword parameter when you call spec-plot, or for
convenience, you can change this variable which will affect all future calls to
spec-plot where the keyword parameter is omitted.*spec-plot-db*spec-plot displays magnitude on a linear scale, but there is an option to
display on a dB scale. You can change the default behavior by setting this variable to
t (true), or you can override the default in any call to
spec-plot using a keyword parameter.s-print-tree(sound) [SAL](s-print-tree sound) [LISP]snd-print-tree.
Nyquist includes many low-level functions that are used to implement the functions and behaviors described in previous sections. For completeness, these functions are described here. Remember that these are low-level functions that are not intended for normal use. Unless you are trying to understand the inner workings of Nyquist, you can skip this section.
The basic operations that create sounds are described here.
snd-const(value, t0, srate,
duration) [SAL](snd-const value t0 srate duration) [LISP]pwl (see Section Piece-wise Approximations) instead.
snd-read(filename, offset, t0, format,
channels, mode, bits, swap, sr,
dur) [SAL](snd-read filename offset t0 format channels mode bits swap sr dur) [LISP](/ (float N) sr (/ bits 8) channels)
If the header is not a multiple of the frame size, either write a header or
contact the author ([email protected]) for assistance. Nyquist will
round offset to the nearest sample. The resulting sound will start at
time t0. If a header is found, the file will be interpreted according
to the header information. If no header was found, channels tells how
many channels there are, the samples are encoded according to mode, the
sample length is bits, and sr is the sample rate. The swap flag is 0 or 1, where 1 means to swap sample bytes. The duration to
be read (in seconds) is given by dur. If dur is longer than the
data in the file, then a shorter duration will be returned. If the file
contains one channel, a sound is returned. If the file contains 2 or more
channels, an array of sounds is returned. Note: you probably want to
call s-read (see Section Sound File Input and Output) instead of
snd-read. Also, see Section Sound File Input and Output for information on the
mode and format parameters.
snd-save(expression, maxlen,
filename, format, mode, bits, swap, play, progress) [SAL](snd-save expression maxlen filename format mode bits swap play progress) [LISP]*RSLT* is bound to a list containing the sample rate,
number of channels, and duration (in that order) of the saved sound.
Note: you probably want to call
s-save (see Section Sound File Input and Output) instead. The format and
mode parameters are described in Section Sound File Input and Output.snd-overwrite(expression, maxlen, filename, offset, progress) [SAL](snd-overwrite expression maxlen filename offset progress) [LISP]*RSLT* is bound to a list containing the
duration of the written sound (which may not be the duration of the sound
file).
Use s-add-to (in Section Sound File Input and Output or
s-overwrite (in Section Sound File Input and Output instead of this function.snd-coterm(s1, s2) [SAL](snd-coterm s1 s2) [LISP]s-add-to, we need to read from the
target sound file, add the sounds to a new sound, and overwrite the result
back into the file. We only want to write as many samples into the file as
there are samples in the new sound. However, if we are adding
in samples read from
the file, the result of a snd-add in Nyquist will have the maximum
duration of either sound. Therefore, we may read to the end of the file.
What we need is a way to truncate the read, but we cannot easily do that,
because we do not know in advance how long the new sound will be. The
solution is to use snd-coterm, which will allow us to truncate the
sound that is read from the file (s1) according to the duration of the
new sound (s2). When this truncated sound is added to the new sound,
the result will have only the duration of the new sound, and this can be
used to overwrite the file. This function is used in the implementation of
s-add-to, which is defined in runtime/fileio.lsp.(snd-from-array ...) [SAL](snd-from-array ...) [LISP]snd-white(t0, sr, d) [SAL](snd-white t0 sr d) [LISP]noise (see Section More Behaviors).snd-zero(t0, srate) [SAL](snd-zero t0 srate) [LISP]pwl (see Section Piece-wise Approximations) instead.
This next set of functions take sounds as arguments, operate on them, and return a sound.
snd-abs(sound) [SAL](snd-abs sound) [LISP]s-abs instead. (See Section More Behaviors.)snd-sqrt(sound) [SAL](snd-sqrt sound) [LISP]s-sqrt instead. (See Section More Behaviors.)snd-add(sound1, sound) [SAL](snd-add sound1 sound) [LISP]sim or sum instead of snd-add (see Section Combination and Time Structure).snd-offset(sound, offset) [SAL](snd-offset sound offset) [LISP]sum instead (see Section Combination and Time Structure).snd-avg(sound, blocksize, stepsize, operation) [SAL](snd-avg sound blocksize stepsize operation) [LISP]s-avg instead (see Section More Behaviors). The s-avg function extends snd-avg to multichannel input sounds.snd-clip(sound, peak) [SAL](snd-clip sound peak) [LISP]clip instead (see Section More Behaviors).snd-compose(f, g) [SAL](snd-compose f g) [LISP]sref, shape, and
snd-resample.
For an extended example that uses snd-compose for variable pitch shifting,
see demos/pitch_change.htm.
snd-tapv(sound, offset, vardelay, maxdelay) [SAL](snd-tapv sound offset vardelay maxdelay) [LISP]FIXNUM or FLONUM)
and vardelay (a SOUND). The specified delay is adjusted to lie in the range
of zero to maxdelay seconds to yield the actual delay, and the delay is
implemented using linear interpolation. This function was designed specifically
for use in a chorus effect: the offset is set to half of maxdelay, and
the vardelay input is a slow sinusoid. The maximum delay is limited to
maxdelay, which determines the length of a fixed-sized buffer. The function
tapv is equivalent and preferred (see Section Filter Behaviors).snd-tapf(sound, offset, vardelay, maxdelay) [SAL](snd-tapf sound offset vardelay maxdelay) [LISP]snd-tapv except there is no linear interpolation. By
eliminating interpolation, the output is an exact copy of the input with no filtering
or distortion. On the other hand, delays jump by samples causing samples to double or
skip even when the delay is changed smoothly.snd-copy(sound) [SAL](snd-copy sound) [LISP]snd-down(srate, sound) [SAL](snd-down srate sound) [LISP]force-srate (see Section Sound Synthesis).snd-exp(sound) [SAL](snd-exp sound) [LISP]s-exp instead (see Section More Behaviors).snd-follow(sound, floor, risetime, falltime, lookahead) [SAL](snd-follow sound floor risetime falltime lookahead) [LISP]snd-avg above for a function that can help to generate a low-sample-rate input for snd-follow. See snd-chase in Section Filters for a related filter.snd-gate(sound, lookahead, risetime, falltime, floor, threshold) [SAL](snd-gate sound lookahead risetime falltime floor threshold) [LISP]snd-gate is not recommended for direct use. Use
gate instead (see Section Miscellaneous Functions).snd-inverse(signal, start, srate) [SAL](snd-inverse signal start srate) [LISP]snd-inverse operationally as follows: for each output time point t, scan ahead in signal until the value of signal exceeds t. Interpolate to find an exact time point x from signal and output x at time t. This function is intended for internal system use in implementing time warps.snd-log(sound) [SAL](snd-log sound) [LISP]s-log instead (see Section More Behaviors).peak(expression, maxlen) [SAL](peak expression maxlen) [LISP]s-save). Only the
first maxlen samples are evaluated. The expression is
automatically quoted (peak is a macro), so do not quote this
parameter. If expression is a variable, then the global
binding of that variable will be used. Also, since the variable
retains a reference to the sound, the sound will be evaluated and left
in memory. See Section Memory Space and Normalization on Memory Space and Normalization for examples.snd-max(expression, maxlen) [SAL](snd-max expression maxlen) [LISP]snd-save), which is therefore normally quoted by the caller. At most maxlen samples are computed. The result is the maximum of the absolute values of the samples. Notes: It is recommended to use peak (see above) instead. If you want to find the maximum of a sound bound to a local variable and it is acceptable to save the samples in memory, then this is probably the function to call. Otherwise, use peak.snd-maxv(sound1, sound2) [SAL](snd-maxv sound1 sound2) [LISP]s-max instead (see Section
More Behaviors).snd-normalize(sound) [SAL](snd-normalize sound) [LISP]snd-oneshot(sound, threshold, ontime) [SAL](snd-oneshot sound threshold ontime) [LISP]snd-prod(sound1, sound2) [SAL](snd-prod sound1 sound2) [LISP]mult or
prod instead (see Section Sound Synthesis). Sample rate, start time, etc. are taken from sound.snd-pwl(t0, sr,
lis) [SAL](snd-pwl t0 sr lis) [LISP]LVAL) where the
list alternates sample numbers (FIXNUMs, computed in samples
from the beginning of the pwl function) and values (the value of the pwl
function, given as a FLONUM). There is an implicit starting
point of (0, 0). The list must contain an odd number of points, the omitted
last
value being implicitly zero (0). The list is assumed to be well-formed. Do
not call this function. Use pwl instead (see Section Piece-wise Approximations).snd-quantize(sound, steps) [SAL](snd-quantize sound steps) [LISP]snd-recip(sound) [SAL](snd-recip sound) [LISP]recip instead (see Section More Behaviors).snd-resample(f,
rate) [SAL](snd-resample f rate) [LISP]resample instead.snd-resamplev(f, rate, g) [SAL](snd-resamplev f rate g) [LISP]sound-warp for a detailed discussion. See
snd-compose for a fast, low-quality alternative to this function.
Normally, you should use sound-warp instead of this function.snd-scale(scale, sound) [SAL](snd-scale scale sound) [LISP]scale instead (see Section
Sound Synthesis).snd-shape(signal, table, origin) [SAL](snd-shape signal table origin) [LISP]shape is based. The snd-shape function is like shape except that signal and table must be (single-channel) sounds. Use shape instead (see Section Filter Behaviors).snd-up(srate, sound) [SAL](snd-up srate sound) [LISP]force-srate (see Section Sound Synthesis).snd-xform(sound, sr, time, start,
stop, scale) [SAL](snd-xform sound sr time start stop scale) [LISP]snd-t0) of the sound is shifted to
time, (1) the sound is stretched as a result of setting the sample rate
to sr (the start time is unchanged by this), (3) the sound is clipped
from start to stop, (4) if start is greater than time, the sound is shifted
shifted by time - start, so that the start time is time, (5) the
sound is scaled by scale. An empty (zero) sound at time will be
returned if all samples are clipped. Normally, you should accomplish all
this using transformations. A transformation applied to a sound has no
effect, so use cue to create a transformable sound (see Section
Using Previously Created Sounds).snd-yin(sound, minstep, maxstep, rate) [SAL](snd-yin sound minstep maxstep rate) [LISP]yin. See Section More Behaviors.
These are also “Signal Operators,” the subject of the previous section, but there are so many filter functions, they are documented in this special section.
Some filters allow time-varying filter parameters. In these functions, filter coefficients are calculated at the sample rate of the filter parameter, and coefficients are not interpolated.
snd-alpass(sound, delay, feedback) [SAL](snd-alpass sound delay feedback) [LISP]snd-delay. The feedback should be less than one to avoid exponential amplitude blowup. Delay is rounded to the nearest sample. You should use alpass instead (see Section Filter Behaviors).snd-alpasscv(sound, delay,
feedback) [SAL](snd-alpasscv sound delay feedback) [LISP]alpass instead (see Section Filter Behaviors).snd-alpassvv(sound, delay, feedback, maxdelay) [SAL](snd-alpassvv sound delay feedback maxdelay) [LISP]FLONUM parameter, maxdelay, that gives an upper bound on the value of delay. Note: delay must remain between zero and maxdelay. If not, results are undefined, and Nyquist may crash. You should use alpass instead (see Section Filter Behaviors).snd-areson(sound, hz, bw,
normalization) [SAL](snd-areson sound hz bw normalization) [LISP]areson
unit generator in Csound. The snd-areson filter is an exact
complement of snd-reson such that if both are applied to the
same signal with the same parameters, the sum of the results yeilds
the original signal. Note that because of this complementary design,
the power is not normalized as in snd-reson. See snd-reson
for details on normalization. You should use areson instead (see
Section Filter Behaviors).snd-aresoncv(sound, hz, bw,
normalization) [SAL](snd-aresoncv sound hz bw normalization) [LISP]snd-areson except
the bw (bandwidth) parameter is a sound. Filter coefficients are
updated at the sample rate of bw. The “cv” suffix stands for Constant,
Variable, indicating that hz and bw are constant (a number) and
variable (a sound), respectively. This naming convention is used throughout.
You should use areson instead (see
Section Filter Behaviors).snd-aresonvc(sound, hz, bw,
normalization) [SAL](snd-aresonvc sound hz bw normalization) [LISP]snd-areson except
the hz (center frequency) parameter is a sound. Filter coefficients are
updated at the sample rate of hz.
You should use areson instead (see
Section Filter Behaviors).snd-aresonvv(sound, hz, bw,
normalization) [SAL](snd-aresonvv sound hz bw normalization) [LISP]snd-areson except
both hz (center frequency) and bw (bandwidth) are sounds. Filter
coefficients are updated at the next sample of either hz or bw.
You should use areson instead (see
Section Filter Behaviors).snd-atone(sound, hz) [SAL](snd-atone sound hz) [LISP]atone unit generator in Csound. The snd-atone filter is an exact
complement of snd-tone such that if both are applied to the
same signal with the same parameters, the sum of the results yeilds
the original signal. You should use hp instead (see
Section Filter Behaviors).snd-atonev(sound, hz) [SAL](snd-atonev sound hz) [LISP]snd-atone except that the hz cutoff frequency is a sound. Filter
coefficients are updated at the sample rate of hz. You should use
hp instead (see Section Filter Behaviors).snd-biquad(sound, b0, b1, b2, a1, a2, z1init, z2init) [SAL](snd-biquad sound b0 b1 b2 a1 a2 z1init z2init) [LISP]FLONUM. You should probably use one of lowpass2, highpass2, bandpass2, notch2, allpass2, eq-lowshelf, eq-highshelf, eq-band, lowpass4, lowpass6, lowpass8, highpass4, highpass6, or highpass8, which are all based on snd-biquad and described in Section Filter Behaviors. For completeness, you will also find biquad and biquad-m described in that section.snd-chase(sound, risetime, falltime) [SAL](snd-chase sound risetime falltime) [LISP]snd-chase function is safe for ordinary use. See snd-follow in Section Signal Operations for a related function. snd-congen(gate, risetime, falltime) [SAL](snd-congen gate risetime falltime) [LISP]congen instead (see Section Filter Behaviors.snd-convolve(sound, response) [SAL](snd-convolve sound response) [LISP]convolve instead (see Section
Filter Behaviors).snd-delay(sound, delay, feedback) [SAL](snd-delay sound delay feedback) [LISP]feedback-delay instead (see Section Filter Behaviors)snd-delaycv(sound, delay,
feedback) [SAL](snd-delaycv sound delay feedback) [LISP]feedback-delay instead (see Section Filter Behaviors).snd-reson(sound, hz, bw, normalization) [SAL](snd-reson sound hz bw normalization) [LISP]reson unit generator in Csound.
The normalization parameter must be an integer and (like in Csound)
specifies a scaling factor. A value of 1 specifies a peak amplitude
response of 1.0; all frequencies other than hz are attenuated. A
value of 2 specifies the overall RMS value of the amplitude response
is 1.0; thus filtered white noise would retain the same power. A value of
zero specifies no scaling. The result sample rate, start time, etc. are takend from sound.
You should use reson instead (see Section
Filter Behaviors).snd-resoncv(sound, hz, bw,
normalization) [SAL](snd-resoncv sound hz bw normalization) [LISP]snd-reson except
bw (bandwidth) is a sound. Filter coefficients are updated at the
sample rate of bw. You should use reson instead (see Section
Filter Behaviors).snd-resonvc(sound, hz, bw,
normalization) [SAL](snd-resonvc sound hz bw normalization) [LISP]snd-reson except
hz (center frequency) is a sound. Filter coefficients are updated at the
sample rate of hz. You should use reson instead (see Section
Filter Behaviors).snd-resonvv(sound, hz, bw,
normalization) [SAL](snd-resonvv sound hz bw normalization) [LISP]snd-reson except
botth hz (center frequency) and bw (bandwidth) are sounds. Filter
coefficients are updated at the next sample from either hz or bw. You should use reson instead (see Section
Filter Behaviors).snd-stkchorus(sound, delay, depth, freq, mix) [SAL](snd-stkchorus sound delay depth freq mix) [LISP]FIXNUM
representing the median desired delay length in samples. A typical
value is 6000. The FLONUM parameters depth and freq set the modulation
depth (from 0 to 1) and modulation frequency (in Hz), mix sets the mixture
of input sound and chorused sound, where a value of 0.0 means input sound
only (dry) and a value of 1.0 means chorused sound only (wet).
You should use stkchorus instead
(see Section Effects).snd-stkpitshift(sound, shift, mix) [SAL](snd-stkpitshift sound shift mix) [LISP]FLONUM representing the shift factor. A value of 1.0 means
no shift. The parameter mix sets the mixture of input and shifted sounds.
A value of 0.0 means input only (dry) and a value of 1.0 means shifted
sound only (wet). You should use pitshift instead
(see Section Effects).snd-stkrev(rev-type, sound, decay, mix) [SAL](snd-stkrev rev-type sound decay mix) [LISP]FIXNUM ranging from zero to
two and selects the type of reverb. Zero selects NRev type, one selects JCRev,
and two selects PRCRev. The input sound is processed by the reverb with
a decay time in seconds (a FLONUM). The mix, a FLONUM,
sets the
mixture of dry input and reverb output. A value of 0.0 means input only (dry)
and a value of 1.0 means reverb only (wet). The sample rate
is that of sound. You
should use nrev, jcrev or prcrev instead (see
Section Effects).snd-tone(sound, hz) [SAL](snd-tone sound hz) [LISP]lp instead (see Section
Filter Behaviors).snd-tonev(sound, hz) [SAL](snd-tonev sound hz) [LISP]snd-tone except hz (cutoff frequency) is a sound.
The filter coefficients are updated at the sample rate of hz. You
should use lp instead (see Section
Filter Behaviors).
These functions all use a sound to describe one period of a periodic waveform. In the current implementation, the sound samples are copied to an array (the waveform table) when the function is called. To make a table-lookup oscillator generate a specific pitch, we need to have several pieces of information:
sim and sine, then the
physical and logical stop times will be the same and will correspond to the
duration you specified, rounded to the nearest sample.) fmosc function is linear, thus calling for a specification in Hertz.Other parameters common to all of these oscillator functions are:
snd-amosc(sound, step, sr, hz, t0,
am, phase) [SAL](snd-amosc sound step sr hz t0 am phase) [LISP]amosc instead (see
Section Oscillators).snd-fmosc(s, step, sr, hz, t0, fm,
phase) [SAL](snd-fmosc s step sr hz t0 fm phase) [LISP]fmosc
instead (see Section Oscillators).snd-fmfb(t0, hz, sr, index, dur) [SAL](snd-fmfb t0 hz sr index dur) [LISP]FLONUM that
specifies the amount of feedback. You should use fmfb instead (see
Section Oscillators).snd-fmfbv(t0, hz, sr, index)(snd-fmfv t0 hz sr index) [LISP]SOUND that
specifies the amount of feedback and determines the duration.
You should use fmfb instead (see Section Oscillators).snd-buzz(n, sr, hz, t0, fm) [SAL](snd-buzz n sr hz t0 fm) [LISP]buzz
instead (see Section Oscillators).snd-pluck(sr, hz, t0, d,
final-amp) [SAL](snd-pluck sr hz t0 d final-amp) [LISP]pluck instead (see Section
Oscillators).snd-osc(s, step, sr, hz, t0, d, phase) [SAL](snd-osc s step sr hz t0 d phase) [LISP]osc instead (see Section
Oscillators).snd-partial(sr, hz, t0, env) [SAL](snd-partial sr hz t0 env) [LISP]snd-amosc that generates a sinusoid starting at phase
0 degrees. The env parameter gives the envelope or any other amplitude
modulation. You should use partial instead (see Section
Oscillators).snd-sine(t0, hz, sr, d) [SAL](snd-sine t0 hz sr d) [LISP]snd-osc that always generates a sinusoid with initial
phase of 0 degrees. You should use sine instead (see Section
Oscillators).snd-sampler(s, step,
start, sr, hz, t0, fm, npoints) [SAL](snd-sampler s step start sr hz
t0 fm npoints) [LISP]sampler
instead (see Section Oscillators).snd-siosc(tables, sr, hz, t0,
fm) [SAL](snd-siosc tables sr hz t0 fm) [LISP]siosc instead (see Section Oscillators).
snd-phasevocoder(s,
map, fftsize, hopsize mode) [SAL]phasevocoder
except that fftsize, hopsize and mode are not optional.
Specify -1 to get
the default values for fftsize and hopsize. Specify 0 for the
default value of mode. You should use phasevocoder instead
(see Section Phase Vocoder).
These functions perform some sort of physically-based modeling synthesis.
snd-bandedwg(freq, bowpress-env, preset, sr) [SAL](snd-bandedwg freq bowpress-env preset sr) [LISP]FLONUM in Hz, bowpress-env is
a SOUND that ranges from zero to one, preset is a FIXNUM,
and sr is the desired sample rate in Hz. Currently, there are four
presets: uniform-bar (0), tuned-bar (1), glass-harmonica (2), and
tibetan-bowl (3). You should use wg-uniform-bar, wg-tuned-bar,
wg-glass-harm, or wg-tibetan-bowl instead (see Section
Physical Models).
snd-bowed(freq,
bowpress-env, sr) [SAL](snd-bowed freq bowpress-env sr) [LISP]FLONUM in Hertz, bowpress-env is a
SOUND that ranges from z
ero to one, and sr is the desired sample rate (a FLONUM).
You should use bowed instead (see Section Physical Models).snd-bowed-freq(freq, bowpress-env, freq-env, sr) [SAL](snd-bowed-freq freq bowpress-env freq-env sr) [LISP]snd-bowed but with
an additional parameter for continuous frequency control. You should use
bowed-freq instead (see Section Physical Models).snd-clarinet(freq, breath-env, sr) [SAL](snd-clarinet freq breath-env sr) [LISP]FLONUM in Hertz,
breath-env is
a SOUND that ranges from zero to one, and sr is the
desired sample
rate (a FLONUM). You should use clarinet instead
(see Section
Physical Models).snd-clarinet-freq(freq, breath-env, freq-env, sr) [SAL](snd-clarinet-freq freq breath-env freq-env sr) [LISP]snd-clarinet but with
an additional parameter for continuous frequency control. You should use
clarinet-freq instead (see Section Physical Models).snd-clarinet-all(freq, vibrato-freq,
vibrato-gain, freq-env, breath-env, reed-stiffness, noise, sr) [SAL](snd-clarinet-all freq vibrato-freq vibrato-gain freq-env breath-env reed-stiffness noise sr) [LISP]snd-clarinet-freq but with
additional parameters for vibrato generation and continuous control of
reed stiffness and breath noise. You should use
clarinet-all instead (see Section Physical Models).snd-flute(freq,
breath-env, sr) [SAL](snd-flute freq breath-env sr) [LISP]FLONUM in Hertz, breath-env is a SOUND
that ranges from zero to one, and sr is
the desired sample rate (a FLONUM). You should use flute
instead (see Section Physical Models).snd-flute-freq(freq, breath-env,
freq-env, sr) [SAL](snd-flute-freq freq breath-env freq-env sr) [LISP]snd-flute but with
an additional parameter for continuous frequency control. You should use
flute-freq instead (see Section Physical Models).snd-flute-all(freq, vibrato-freq, vibrato-gain, freq-env, breath-env, jet-delay, noise, sr) [SAL](snd-flute-all freq vibrato-freq vibrato-gain freq-env breath-env jet-delay noise sr) [LISP]snd-flute-freq but with
additional parameters for vibrato generation and continuous control of
breath noise. You should use
flute-all instead (see Section Physical Models).snd-mandolin(t0, freq, dur, body-size, detune, sr) [SAL](snd-mandolin t0 freq dur body-size detune sr) [LISP]FLONUM in
Hz, body-size and detune are FLONUMs, and sr
is the desired sample
rate. You should use mandolin instead (see Section Physical Models).snd-modalbar(t0, freq, preset, dur, sr) [SAL](snd-modalbar t0 freq preset dur sr) [LISP]FLONUM in Hz,
preset is a FIXNUM ranging from 0 to 8, dur is a
FLONUM that
sets the duration (in seconds) and sr is the desired sample rate. You
should use modalbar instead (see Section Physical Models).snd-sax(freq, breath-env, sr) [SAL](snd-sax freq breath-env sr) [LISP]FLONUM in Hertz, breath-env is
a SOUND that ranges from zero to one, and sr is the desired sample
rate (a FLONUM). You should use sax instead (see Section
Physical Models).snd-sax-freq(freq, freq-env, breath-env,
sr) [SAL](snd-sax-freq freq freq-env breath-env sr) [LISP]snd-sax but with
an additional parameter for continuous frequency control. You should use
sax-freq instead (see Section Physical Models).snd-sax-all(freq, vibrato-freq,
vibrato-gain, freq-env, breath-env, reed-stiffness, noise, blow-pos, reed-table-offset, sr) [SAL](snd-sax-all freq vibrato-freq vibrato-gain freq-env breath-env reed-stiffness noise blow-pos reed-table-offset sr) [LISP]snd-sax-freq but with
additional parameters for vibrato generation and continuous control of
reed stiffness, breath noise, excitation position, and reed table offset.
You should use
sax-all instead (see Section Physical Models).snd-sitar(t0,
freq, dur, sr) [SAL](snd-sitar t0 freq dur sr) [LISP]FLONUM (in Hz), E
dur sets the duration and sr is the sample rate (in Hz)
of the resulting sound. You should use sitar instead (see Section
Physical Models).
The next two functions are used to implement Nyquist's seq construct.
snd-seq(sound, closure) [SAL](snd-seq sound closure) [LISP]snd-multiseq(array, closure) [SAL](snd-multiseq array closure) [LISP]snd-seq except the first parameter is a
multichannel sound rather than a single sound. A multichannel sound is
simply an XLISP array of sounds. An array of sounds is returned which is
the sum of array and another array of sounds returned by closure.
The closure is passed the logical stop time of the multichannel sound,
which is the maximum logical stop time of any element of array.
The sample rates and number of channels returned from the closure must
match the first multi-channel sound in the sequence.
Do not call this function directly.